How to Architect for Sustainability in a Cloud Native Environment
Published 05/16/2022
 This blog was originally published by Contino here.
This blog was originally published by Contino here.
Written by Scott McCracken, Contino.
Recognising the impact we have on the environment is more important than ever and ensuring our businesses are sustainable is now paramount. Over the last year, more and more organisations have signed up to The Climate Pledge, promising to achieve net-zero carbon by 2040.
Optimising how we build and use IT infrastructure will play a big part in achieving these goals and adopting the public cloud can help organisations accelerate and improve on their sustainability measure.
Sustainability in the cloud is a shared responsibility. It is up to the cloud providers to ensure their data centres & underlying global infrastructure run as efficiently as possible. It is up to us as builders to ensure that we are architecting, designing and building sustainable ecosystems.
In this blog, we are going to delve into seven things we can do as technologists when architecting and building solutions in the cloud to align with our organisations’ sustainability goals.
1. Favour Serverless Based Architectures and Managed Services
Serverless architectures allow you to use only the resources you need, when you need them. This comes with many benefits—cost reduction, scalability, reduction in security overhead—and it also helps us improve our sustainability posture.
This is simply because we don’t use as much electricity as we would in traditional server-based architectures.
So when looking at your chosen cloud provider, look to their serverless based offerings, such as:
- AWS - Lambda and Fargate
- Azure - Functions and Container Instances
- GCP - Cloud Functions and Cloud Run
2. Enable Observability
How can we be sure the decisions we are making are actually causing a reduction in the use of our carbon footprint? How do we know that a tweak to optimise our code has actually reduced compute resource power? To do this, we must be able to understand and observe our systems in depth.
Check out our recent Ultimate Guide to Observability to understand what observability is, and why you should be building monitoring into everything you do.
Cloud providers are also rapidly introducing tools that help us understand our carbon footprint in the cloud:
- AWS announced at re:Invent 2021 that it would soon be releasing a Customer Carbon Footprint tool
- Azure introduced a Sustainability Calculator in 2020
- GCP released its Carbon Footprint Tool in October 2021
3. Review the Service Level Agreements and Disaster Recovery Plans
As we architect for certain levels of availability and decide on our operational resilience requirements, we now must take into consideration the impact they are having on the environment. This often comes down to how much idle compute power we require to run. When architecting for resilience, we can begin questioning our requirements with the sustainability impact required to run them in mind. Two examples are laid out below.
Do we require instant failover to another region or can we consider non-instant failover?
The cloud is a huge enabler for automated failover. When we are considering failing over to another region, we have many options.
We could have instances running constantly in two regions that have enough capacity to handle the load of the entire system; this will allow us to instantly failover to another region in the case of failure. However, it comes at a huge wasted cost, both monetary and environmentally as we are consuming a large number of resources that will sit idle.
Alternatively, we could run our failover in a non-instant way. With the power of the cloud, we can be back up and running in a matter of minutes, with no human intervention. Rather than having both regions in an active-active setup, we instead run our workloads in one region and automate the failover to another.
There is of course a trade-off. We are no longer able to failover with zero downtime, but we can failover in a matter of minutes, with huge cost and environmental savings. Given that entire regions in most cloud providers have extremely high SLA times (such as AWS being 99.99% uptime for EC2 across two or more Availability Zones), is this manner of automated failover going to allow us to still achieve our SLAs?
Can we optimise the placement of our workloads and the number of instances so that our workloads require less idle compute power?
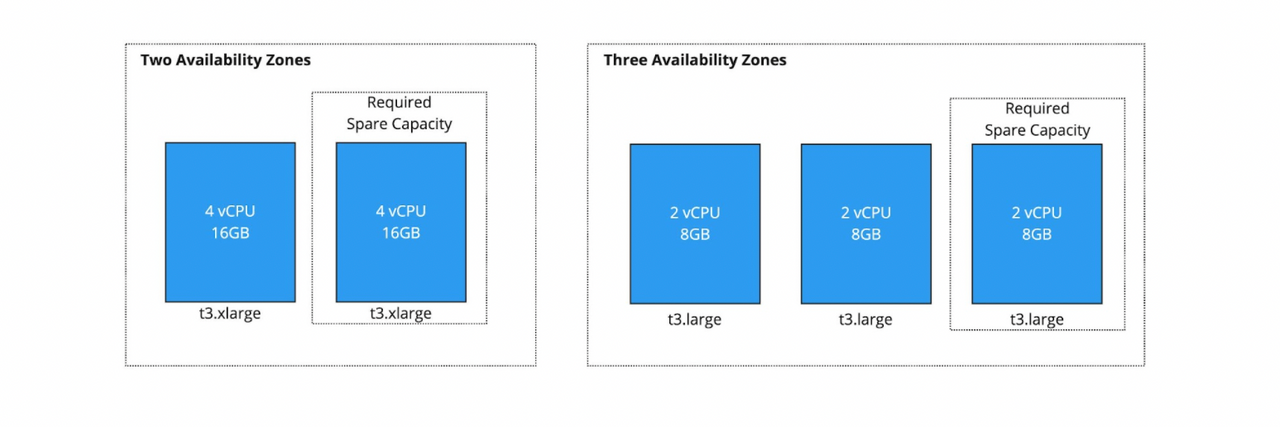
For example, consider an application that requires a maximum of four vCPUs and 16GB of RAM to run and requires instant failover in the event that one AZ goes offline. Which requires less idle compute power; spreading the load across two or three AZs?
As shown in the diagram below, two AZs would require an excess of four vCPUs and 16GB of RAM, ensuring each AZ has the full capacity to handle the load.
Three AZs would only require the excess capacity of two vCPUs and 8GB of RAM on standby since, in the event of failure, we will still have two instances running. Therefore, there is a reduction in the excess capacity if we were to use 3 AZs.
4. Automate Data Retention Policies
The amount of data we generate is growing exponentially. The amount of this data we store is also growing at a huge rate and it is forecasted to continue doing so for the years to come. More data being stored means more computing power and more energy to store it.
Public cloud providers allow us to automate the retention of this data through a number of solutions. This ensures we are retaining data for a suitable amount of time as may be required by many regulatory requirements, such as GDPR, but also helps ensure we don’t use unnecessary compute power.
Look at technologies such as S3 lifecycle policies for AWS, Object Lifecycle Management in Google Cloud Storage and Lifecycle Management Policies in Azure Blob Storage to help you achieve this.
5. Choose Regions with Low Carbon Emissions
When deciding on a region, we often take into consideration cost and latency. We should also be considering what regions are running in the most sustainable way.
Earlier this year, Google Cloud made this simple in their ecosystem by publishing carbon free percentages on a per-region basis. AWS made this is one of the best practices published in AWS’s sustainability pillar. As we see further development in cloud carbon footprint tooling, I suspect this will become easier than ever to measure.
6. Adopt A Mature Deployment Approach
As we develop and deploy our applications to production, we promote through multiple long lived environments, such as development, test, user acceptance testing, performance testing, staging and often many more.
Many of these environments are only used for short periods of time, for example, to run short-lived automated tests. As we develop our environment strategy, it’s important to ask ourselves which of these environments are truly offering us value? Do we need to run each of these tests in different environments? Ensuring we keep the number of environments to a minimum will help us with both driving down cost and driving down wasted compute power.
If deploying to multiple environments does deliver value, review how their usage can be minimised. Going back to our previous point, favour serverless based architectures and managed services, these often allow us to scale down to zero whilst they are not being used, ensuring no wastage of resources.
7. Adopt Green Software Engineering Principles
The Green Software Foundation is working to build a trusted ecosystem of people, standards, tooling and best practices that help us deliver green software.
The foundation is centred around 8 core principles:
- Carbon: Build applications that are carbon efficient.
- Electricity: Build applications that are energy efficient.
- Carbon Intensity: Consume electricity with the lowest carbon intensity.
- Embodied Carbon: Build applications that are hardware efficient.
- Energy Proportionality: Maximise the energy efficiency of hardware.
- Networking: Reduce the amount of data and distance it must travel across the network.
- Demand Shaping: Build carbon-aware applications.
- Measurement & Optimisation: Focus on step-by-step optimisations that increase the overall carbon efficiency.
They offer best practices, standards, tools and examples on how to make these principles a reality. Check out their website and GitHub repositories for more information.
Migrating to the public cloud is an excellent way to ensure your IT infrastructure is as sustainable as possible. However, it is up to us as architects and engineers to ensure what we build is optimised for sustainability. This will help our businesses meet their sustainability commitments, whilst also ensuring we are making cost-effective, compute-efficient solutions.
With that in mind, review the steps in this article when making architecture decisions. Also, take a look at the advice your chosen cloud provider is issuing when it comes to sustainable architecture:
If you want to find out more about how to leverage the cloud to reduce your ecological cost as a business, you can read our blog on how to use the three Rs of cloud engineering to become a more sustainable business: Reduce, Reuse and Recycle.
And if you’d like to see five real life examples of data-driven solutions to sustainable development goals you can read this blog on how investing in technologies such as cloud computing and machine learning can minimise your organisation’s ecological impact.
Share this content on your favorite social network today!



Unlock Cloud Security Insights
Subscribe to our newsletter for the latest expert trends and updates
Related Articles:

What an AI Lab’s Test Reveals About the Enterprise AI Challenge
Published: 05/13/2026

.jpeg)
What if AI Knew When to Say “I Don’t Know”?
Published: 01/21/2026

Cloud 2026: The Shift to AI Driven, Sovereign and Hyperconnected Digital Ecosystems
Published: 01/15/2026