Runtime is the Way
Published 04/04/2024
Originally published by Sysdig.
Written by James Berthoty.
The cloud security market has been totally bizarre ever since it started. Why are we being given a python script to count our workloads? How do we handle sending alerts like “new unencrypted database” to a SOC? What’s the difference between this tool and the open source options? We’re all learning together about the new processes, tools, and deployments that would define the future.
The idea that cloud resources were distinct from on-prem ones was a gamble, one that paid off massively for the companies that invested in it early. Marketing money helped Cloud Security Posture Management (CSPM) become the must-have tool for cloud security before its gaps were identified. Cloud Native Application Protection Platforms (CNAPP) came along as the way to try and clean up the mess. Gartner defines CNAPP as “a unified and tightly integrated set of security and compliance capabilities designed to secure and protect cloud-native applications across development and production.” In other words, one platform that does everything security and compliance related. But in the cloud, the details of those “capabilities” make a huge difference.
Keep reading to learn:
- Why runtime protection has not historically been top priority for cloud security teams.
- What major objections there are to prioritizing runtime protection.
- Why runtime security is the best return on investment in any cloud tool.
The typical cloud security journey
On the first day of my first cloud security role, the CISO came up to me and said, “I need you to figure out what the devs have been doing, and how to secure it.” That statement perfectly describes most security engineers’ lagging journey into cloud security. The old security world was about managing EDR on Windows servers and SIEMs. The new one required a radically different skillset: one that requires every security engineer to quickly learn skills that aren’t a part of their standard toolkit– from coding to Kubernetes.
I didn’t know it at the time, but “figuring out what the devs are doing” is a massive challenge. How do you build trust? How do you get visibility? How do you get prioritization? More fundamental even than these questions: how do you not feel like an idiot? I scheduled a meeting two weeks out with our chief architect, hoping to figure that out before then.
In order to secure something, you have to know what it is. Unfortunately, knowing what modern applications are is extremely challenging. Very few people in a company can maintain a mental model for their applications. This is why security is stuck in such a difficult position. In order to do your job well, you need to interface with these select people, who are often principal engineers or architects. Because cloud engineering, especially Kubernetes and cloud-native service architecture, is a constantly evolving skill for security professionals, which puts them at a special disadvantage. Oftentimes, someone who has barely used the cloud is providing guidance to someone who is building cutting edge architecture in it.
Graph of uber’s microservices – now secure it?
As a result, from what I’ve seen, almost every company’s first foray into cloud security is driven by fear, prioritizing general visibility over any other capability. Fear is a major motivator, and the insecurity of security can drive the first major purchase. This was certainly the case for myself. Extending a relationship with an existing vendor who let me create an AWS role to check my account for misconfigurations made me feel like I was adding value immediately. It was only once I tried to fix the first finding that I realized I was creating irrelevant busy work for already burdened teams, while starting the security-developer relationship off on a bad foot.
It doesn’t take long for the realization to hit that misconfiguration scanning was never the primary issue ( about as long it took to send the first ticket to developers). Most companies falsely assume that these alerts should go to the SOC, who immediately drown in the alerts they can’t do anything about. Because many security teams are learning about the cloud via the tool they purchased, they’re not aware until the multi-year contract has kicked in that their developers are all pushing configuration as code, and scanning the configuration at runtime is already too late. Furthermore, their CSPM tool is full of false positives, or more often, minor vulnerabilities that would take months of engineering time to fix.
Security prioritized visibility at runtime, but learned too late that they actually wanted visibility at code time, or “shift-left.” Typically, this leads to the neverending trap of trying to get better and better at detection and visibility, which creates complex ticketing workflows. The reality is you will never hit zero vulnerabilities, but if a tool is scanning your cloud and can’t see the code, then it can’t provide relevant information to the teams who can fix it. For example, in my insecure-app deployment testing repo, deleting a secret key is a one line code change, but at runtime, it might be extremely difficult to see where the environment variable was coming from.
From what I’ve seen, this is where most companies who have adopted cloud security tools are at: they’ve realized their CSPM isn’t providing the value they thought it would because they’re only ever seeing the vulnerability count go up and to the right. At this point, I’ve seen teams go one of two ways: either dive deeper into configuration scanning workflows or cut the loss and prioritize runtime security.
It’s all too easy to get caught up on the vulnerability count and hyper-fixate on the question, “How can I make this go down?” However, this misses the core question, “Does making this graph go down actually do anything?” To help illustrate, look at the following cloud application diagram comparing CSPM and runtime protection:
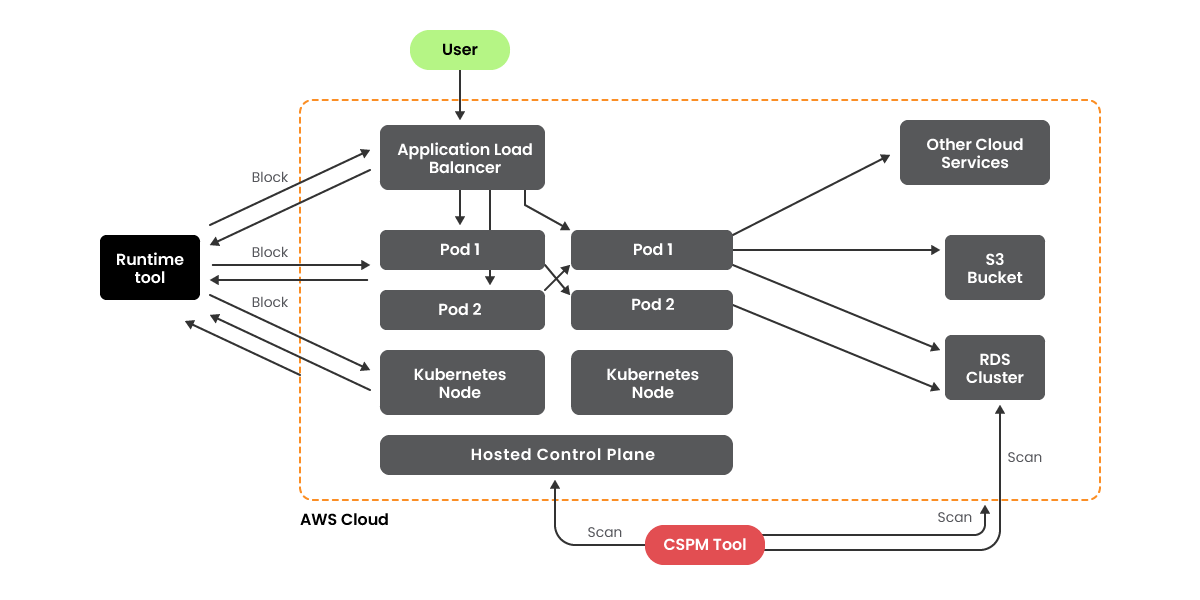
If your goal is to spot or stop an actual attack, there’s a fundamental difference between what CSPM and runtime-oriented tools offer: only one of them has meaningful visibility into the compute layer. Although there’s a lot you can see with cloud APIs and snapshot scanning, you will always have a blindspot if you’re not able to see inside Kubernetes pods and what they’re doing.
Critically, runtime tools don’t merely gain response functionality; they also offer greater visibility than CSPM by looking at log data across every service and compute directly. So why don’t security teams use them? First, it’s the story I shared earlier – visibility is often the first major evaluation criteria for security teams. However, there are some objections to taking a runtime first approach.
Answering objections to runtime tools
I recently asked on LinkedIn about why selling runtime is harder than visibility, and here’s a categorization of the responses:
- Showing the value of runtime is too slow and difficult.
- Customers feel like they need to get visibility done first.
- Blocking things is scary.
- Installing agents is hard.
- Using non-k8s agents in a k8s environment is a bad time.
Anton Chuvakin’s comment summed it up the best: “Runtime protection is seen as higher risk AND MUCH higher burden for deployment.”
Showing the value of runtime is too hard
In my brief but fun time selling a security scanning solution, I learned first hand that most people are focused only on their outcome, and during a PoC, (if they even do one) they are rarely focused on the details. If they see a demo showing one piece of detection, they automatically assume that there’s a lot of critical detection happening across the tool. The reason selling runtime is hard is because security teams can be too easily placated with a demo; we often need to be pushed to see the details.
I recently made two videos: one diving into runtime kubernetes security, and another on kubernetes vulnerability scanning. True to nature, the vulnerability scanning tool took less time to get operational, but the overall video is longer because fixing findings is harder than detecting them. The only way to be convinced of the value of runtime is to stay focused on the outcome. Implementing a vulnerability scanner gave me a year’s worth of work to do, while implementing the runtime sensor blocked 90% of the attacks that I otherwise would’ve needed to fix.
All this to say: I’m sympathetic to the idea that showing the value of a runtime tool in a 20 minute sales call is going to be tough, and it requires sellers to instead focus on the outcome you’re going to get out of the tool. You’re not trying to buy more work for your product teams, you’re buying something to stop attacks.
Security teams feel like visibility needs to happen first
I’m sympathetic to this objection; it happened in my own cloud security journey. If I could go back and give myself two pieces of advice, it would be:
- Meaningful visibility happens at the compute layer.
- Developers are primarily not fixing things because it’s really hard, not because they don’t know about it.
Before buying a security tool, shadow a member of your DevOps or SRE team and ask them to show you every tool they have for managing your cloud environment. I guarantee you they have visibility tools and you’ll say, “wow, could I get access to that” more than once on the call.
There’s no such thing as a simple visibility tool because anything simple is going to be missing important compute data and provide the false assurance that you’re seeing what you need to. If you’re prioritizing only the most visibility for the lowest lift, you’re going to buy a tool that just crawls all of your cloud API’s and tries to build a picture of the environment. Maybe they do snapshot scanning and you get some limited visibility into legacy workloads. Ask yourself: if I was an attacker who got a connection to a workload in my environment, do I have any tools that would show me that? We’re looking for visibility to achieve a security outcome, not just for the sake of seeing a dashboard. Also, if your cloud security tool doesn’t have kubernetes or container visibility, it might as well not exist.
Additionally, while visibility can be helpful, the best visibility is a good developer relationship. Developers know where in their code exploits are likely to hide; they just need to be asked about them. This is why I’m helping make an open source AI security scanner; general checks are more helpful than a million tickets.
To summarize: easy visibility is a disaster waiting to happen because it’s misleading. If you can’t see an exploit taking place, can you really say you’re seeing anything? It’s like saying I have a home defense system because a security company gave me a list of cameras I should install. I might feel like I got something, but in reality, I just got more work to do.
Blocking things is scary
The fear of blocking is real, but it’s left over from the WAF and EDR days. A misconfigured WAF rule can completely take down your application, just like an EDR. The Kubernetes Cattle vs Pets rule shouldn’t have only revolutionized ops, but also runtime security. If your agent kills a running process on a web server serving thousands of users, you’re in for a bad time. If your Sysdig agent kills a pod where it saw malicious activity, good news, there are hundreds more ready to take the traffic. EDR in the container world does not need to be as scary as it used to be.
Beyond this, Kubernetes security rules have a bright future, as more and more runtime is being defined as code. You can build models of your container processes and network flows and block deviations. You can set thresholds for agent utilization and responses. No longer does blocking things have to be seen as too scary to implement – it just requires dedication to a kubernetes mindset.
Installing agents is hard
This is another leftover from the pre-Kubernetes days: deploying and maintaining agents was a massive pain. Whether it was trying to run massive Ansible playbooks, or mass deploying via GPO, no one enjoyed the process of getting agents out there. Conversely, Kubernetes makes deploying agents almost fun – and more importantly – a great learning experience for security teams.
Working hand in hand with DevOps installing helm charts is a career-defining learning experience that makes it almost worth buying a runtime tool by itself. Yes, the DevOps team is going to complain initially about installing something new, but everyone always complains about change – they’re going to complain more about the 10 security tickets a quarter coming from a scanner.
While they may complain about a ticket or new agent, no DevOps team has ever complained about their security team learning how to use kubectl and helm. The short term pain of the agent install only stays painful if you truly hand it off to DevOps without getting your hands dirty. Instead of choosing a tool because it doesn’t have a Kubernetes agent, you should choose a tool because it does! The hands-on experience and collaboration is worth more than the tool itself.
Bad experience with old EDRs
Maybe you don’t have a runtime tool because you installed a first generation Kubernetes “integration” with a legacy provider. The install instructions are all beta, the agent is finicky, and the visibility doesn’t seem to matter. It is worth looking at Kubernetes-specific runtime protection vendors; everything from the install to the visibility is better.
The first time I evaluated EDR for Kubernetes environments, I looked at legacy EDR providers, Sysdig, and some other more “cloudy” vendors. While I could get some of the “cloudy” ones working with some very basic alerts (like new namespace created). When it came to the legacy EDR, I literally thought it was broken, and so did their sales team. I was doing heinous things inside a pod – escalating privileges, container escaping, path traversal all with zero alerts. Two years later, I met back with the legacy EDR provider and did another evaluation. They still did not detect a single thing, but this time I learned that they really only looked for ransomware attacks inside containers.
When it comes to EDR for containers, throw all the old assessments out the window: MITRE testing, Gartner Magic Quadrants, flavor of the month buzzwords. Test it yourself using https://github.com/latiotech/insecure-kubernetes-deployments.
ROI on Runtime
Every CNAPP provider uses the same quote these days. They’re all priced similarly and have their own flavor of “workloads.” Unfortunately, it’s hard to measure which CNAPP provider will deliver the biggest ROI.
Here’s why I flip the typical evaluation criteria on its head:
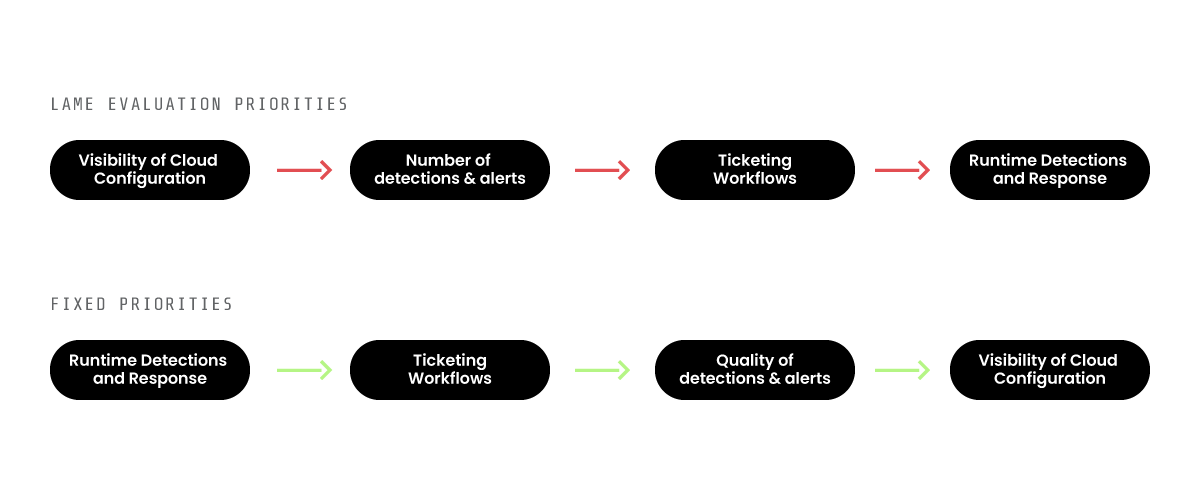
At the end of the day, runtime protects your product team for quarterly work, ticketing workflows allow devs to manage the work themselves, the quality of detections allows for finding misconfigurations, and visibility gives developers extra context. Your goal is to create developer efficiency, whereas the old evaluation priorities create inefficiencies. If you want some basic visibility for getting started, just run Prowler, don’t sign a multi-year CSPM contract.
1. CSPM without runtime is useless.
Of course no one’s going to advertise this, but CNAPP providers were either built on their runtime protection or their cloud scanning. The truth is that your configuration happens in your code, not in your cloud – so stop buying with configuration scanning for your cloud as the primary goal. CSPM visibility can provide some nice features around general application visibility, but the value of CNAPP is what it can do on the actual compute layer of your application. The heart of your cloud security enforcement should be happening through terraform modules and IaC scanning. The heart of your cloud security program should be CNAPP runtime protection.
2. Security is not the end user of configuration scanning – developers are
Many security teams are caught in a downward spiral due to their early investment in CSPM. They’re sitting on a giant pile of alerts, and looking for tools that help them manage those. I call that buying a tool to fix a tool. The fundamental issue is that as a security user, I can’t do anything about the alert I’m seeing. Unless you have a large enough security team that a member is embedded within every development team (no one does this), you will never have enough context to single handedly fix any alert coming from a CSPM. This creates a process problem where you’ve tied up your entire security team as project managers and business analysts – moving tickets around and analyzing vulnerability trends.
Runtime protection differs by giving security something they can actually do. If I see a runtime alert – I can independently take an action, whether that’s investigating, killing a container, or closing a network port. Runtime security empowers your security team to do actual direct and meaningful work.
3. Runtime protection is the only thing that will stop an actual attack
Every interesting investigation – false positive or not – I’ve been a part of has come from a runtime protection tool. I’ve only seen DAST (the good new ones, not the bad old ones) find actual SQL injection or performance issues. I’ve only seen container protections discover suspicious pod activity. I’ve only seen firewalls detect that internal addresses were attempted to be hit from external sources.
You can spend years hardening your services, but for every Log4J level threat, I’ve been grateful to have layered defense options in place. I’ll implement a WAF rule, setup runtime alerting, and configure SIEM detections to buy time to fix the configurations. You know what applications stay closed during major investigations? CSPMs. I code scan, tell my devs what to patch, and buy them time with layers of runtime defense. Because I had runtime solutions, I was able to actually do something besides hand out tickets.
The conclusion of my cloud security journey was evaluating CNAPP entirely on its runtime kubernetes capabilities, virtually ignoring everything else. Configuration alerts are for developers, runtime alerts are for security. Only one of those will actually stop an attack whether I have 0 vulnerabilities or 10,000 of them. I remain absolutely convinced that if you care about the security of your application more than compliance or vulnerability charts, runtime is the way.
Share this content on your favorite social network today!

.png)
.png)
.png)

.png)
Unlock Cloud Security Insights
Subscribe to our newsletter for the latest expert trends and updates
Related Articles:
.jpeg)
Why M2M Authentication and API Security Must Work Together
Published: 07/22/2026
.jpeg)
How AI Governance and Data Governance Are Converging in the Cloud
Published: 06/30/2026

How a Penetration Test Builds Customer Trust & Strengthens ISO 42001 Certification
Published: 05/21/2026

Achieving Complete SDLC Visibility and Security in a Multi-Cloud World
Published: 05/11/2026