Keeping up with log4shell aka CVE-2021-44228 aka the log4j version 2
Published 12/16/2021

Quick note: from now on I will refer to log4j version 2 as “log4j2”
If you use Java within your products or services and haven’t yet patched them, please see “Dealing with log4shell aka CVE-2021-44228 aka the log4j version 2”
Trick question: Who helped coordinate the global response on CVE-2021-44228?
Answer: Two Twitter hashtags: #log4j and #log4shell.
On the Apache Software Foundation side, the log4j developers and the Security Team did a good job, but in classic Apache fashion once they created the update and assigned it a CVE they posted it to their website, emailed a copy to the apache www-announce and another to the oss-security list and… that’s it. There was no significant follow-up or replies from Apache after that. It was up to the community at large to deal with this.
I suspect the reason they operate in this manner is simple: the Apache Software Foundation budget in 2019 was 2.26 million, and I suspect it hasn’t grown significantly in the last 2 years. In other words, a Software Foundation that literally underpins our modern technology-driven world is operating on less than the coffee budget of a major corporation. The Apache Software Foundation handles roughly 140-150 vulnerabilities with CVE IDs per year, and it’s not like they can spend a lot of their budget on security (it’s pretty much 100% volunteer-driven).

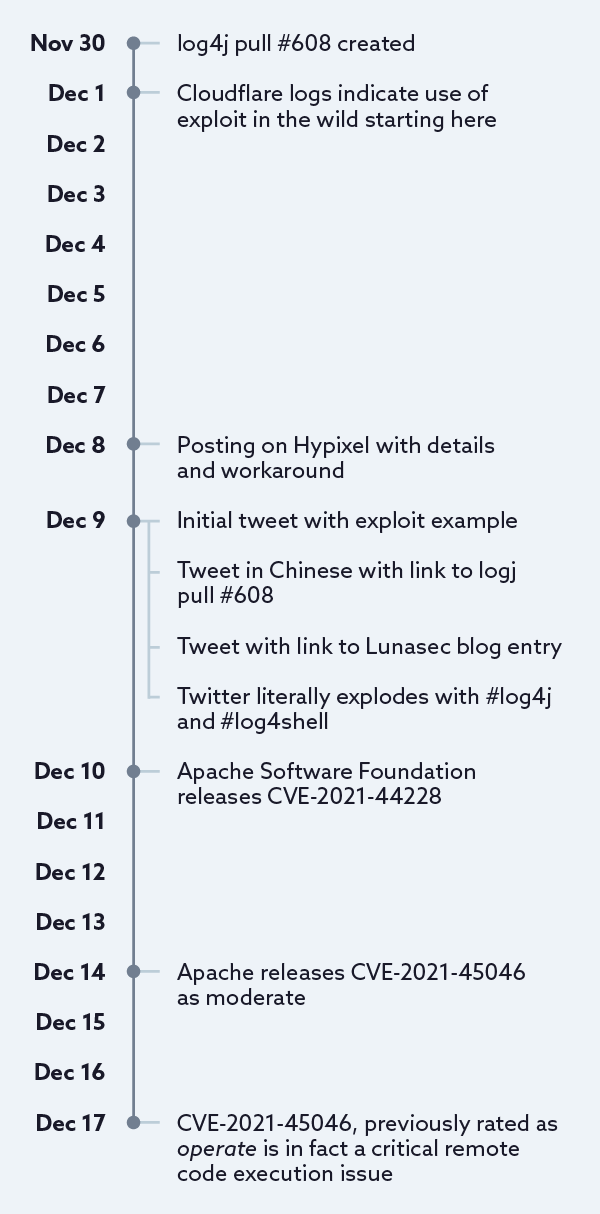
To say the announcement of CVE-2021-44228 landed like a bombshell is an understatement. On Twitter, the activity for CVE-2021-44228 on Dec 9 and 10, 2021 alone was well into the thousands. I got bored waiting for them all to load and gave up after holding down the space bar for a few minutes.
Except this was all a day late and a dollar short, on Dec 9, 2021, this tweet was posted:
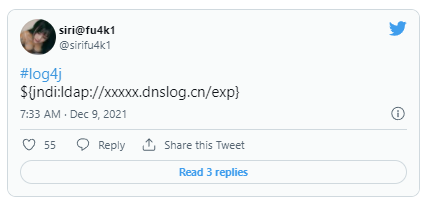
Which contains enough information to craft an exploit, but lacks any real context apart from “exp” at the end hinting at “exploit.” A few hours later a more explicit tweet appeared:
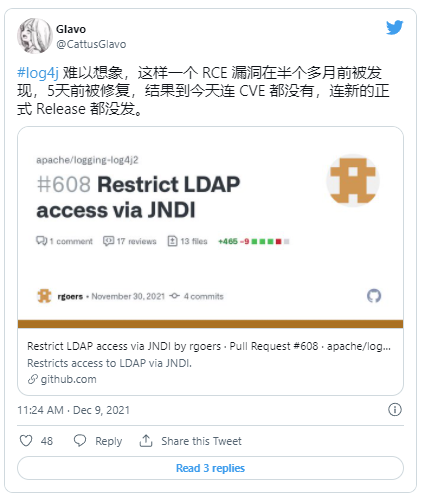
But unless you’re monitoring Chinese language tweets for random technology terms and/or reading every linked GitHub issue you wouldn’t have seen this. But anyone that clicked that link and read issue #608 would have quickly realized just how bad this was (or maybe not, the Apache Software Foundation didn’t make a big deal out of it). An hour later we get the first mention on Twitter of the Lunasec blog posting:
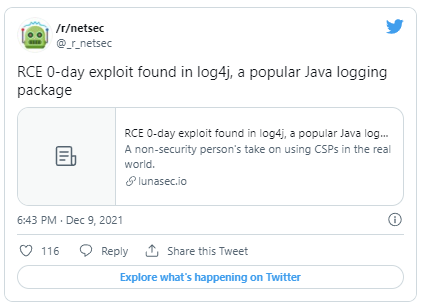
Except even these tweets were old news, it appears that the Minecraft community of all things was experiencing exploitation of this issue, days in advance:
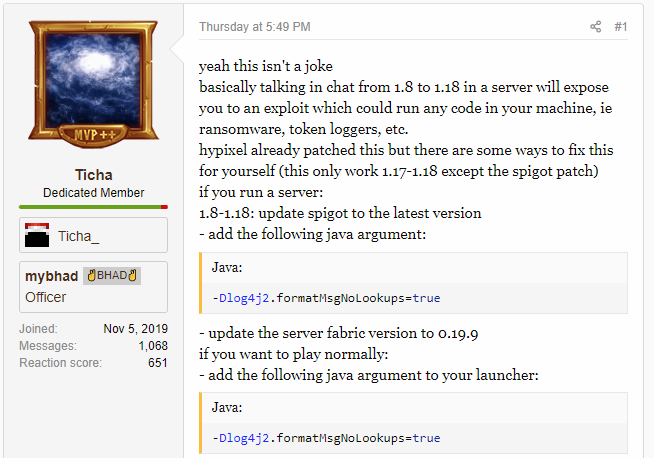
And the workaround was known (which would indicate that the specific details of exploitation were also known) and it was being discussed on discord servers (a talk service popular with gamers) prior to this:
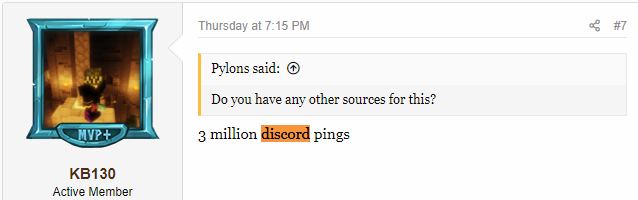
Except even this early discussion of the vulnerability on Discord was also old news. Matthew Prince (CEO of Cloudflare) reported that:
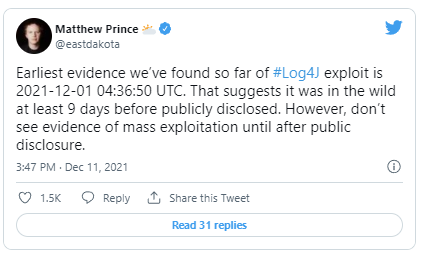
I guess the good news is that there wasn’t quite widespread exploitation of this by a malicious state-level actor prior to all this (e.g. a Solarwinds situation).
But even all of the above was old by the time it came out. The log4j project was notified almost 2 weeks prior that there was an issue, but it wasn’t explicitly clear that it was a security issue, or that it was a severe security issue (indeed, I would say this is the worst issue in the last decade).
So what can we learn from all this?
Communication channels for security, especially in the OpenSource world, have changed. All the mailing lists I relied upon 20 years ago (oss-security, full-disclosure, bugtraq) are either dead or so inactive (just vendor announcements and no real discussion) that they may as well be considered dead. In this instance, and a similar previous one (also from Apache, CVE-2021-41773 & CVE-2021-42013), the main communications channels used by the global InfoSec and IT communities were:
- Twitter (hashtags)
- GitHub (for scanners, exploit code, workarounds, etc.) advertised via twitter
- Reddit (specifically r/netsec and r/sysadmin)
- HackerNew
The CVE database entry is not really useful beyond serving as an initial notification (a very late one at that). It lacks any data about the workarounds (in fact it had a workaround that was then silently removed and re-added a few days later) or the hotpatches, or detection or scanning tools, or anything actionable really beyond a handful of vendor advisory links (a clever incomplete list at that). Conveniently CVE-2021-44228 actually links to one of my tweets on the topic:
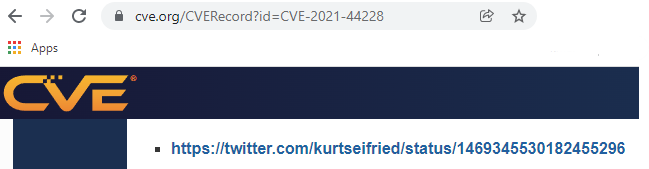
The tweet in question was talking about the GlobalSecurityDatabase entry (GSD-2021-1002352) which had all the details:
So what are we to do? You can’t have your operations team monitoring Discord, Twitter, and GitHub for new repositories, and Reddit, HackerNews and so on for every possible piece of software you may be using. It’s clear that even dedicated security teams and companies can’t do this reliably. Ingesting the CVE data feed or commercial threat intelligence feeds is a good start, but as you can see it is slow and lacks vital information (e.g. the hot patches which even AWS is advocating people to use).
Essentially, the problem is that we have a ‘many producers to many consumers, using many different communications channels’ problem (so you have to monitor a lot of sites for a lot of different things).
But what if some system existed that could collect all the data and become a central point to both publish data, and read it? The CVE database was such an effort, but it has stalled out, both in the amount of data (topping out at 16-18,000 CVEs per year) and updates to the data (there was a 48 hour period where there was almost no activity on CVE-2021-44228, the description is still effectively the same as what was originally published, and there is no mention of other affected products, both in the description or the machine-readable data).
Another interesting aspect of this crisis: there are multiple instances of the CVE-2021-44228 vulnerable products/service lists, workarounds, etc. being listed in various websites and GitHub repos. The clear winners in these are the ones accepting community feedback and publishing it quickly, for example, compare the US CISA list (slow to include updates) to the Dutch Nationaal Cyber Security Centrum (NCSC-NL).
The CISA repo (at the time of writing this) has 6 closed (completed) pull requests and 13 open pull requests, whereas the Dutch NCSC-NL has 317 closed (completed) pull requests and 29 open ones, and even as time goes on and CISA does more work, the Dutch repo has already added more types of data (such as Indicators of Compromise, mitigations, hunting tools, and scanning tools to name a few).
I think this is one of the main reasons that Twitter #log4j and #log4shell won. You can’t stop people from participating, and if they produce reasonably good content it will get people hitting the like button or retweeting it, and thus trend upwards and get even more exposure (classic long-tail distributions, a handful of tweets get most of the eyeballs). Compare this to a traditional system like CVE where every piece of information must be submitted, vetted, and approved by a single entity (that doesn’t appear to work on the weekends) and you have a clear shift in where you need to be getting your information security if you want to stay up to date on the latest crisis.
How do we move forward?
Doing more of the same won’t work that well. We can’t have every private intel threat feed scour all of Twitter, Discord and community forums for possible security flaws, the volume is too high, the signal to noise ratio too low, and there aren’t enough security analysts to handle the resulting flood of “maybe important” stuff. We’ve also tried working with CVE - I’m happy to say I invented the JSON data format they use and I got them to move the data into GitHub, but things have stalled out since then. In fact, MITRE suggested removing the GitHub repo, and still refers to it as the “CVE Automation Working Group Git Pilot” despite using it for almost 4 years.
The Global Security Database (GSD) is a new project from the Cloud Security Alliance meant to address the gaps in the current vulnerability identifier space. One of the biggest differences between the GSD and everything else is that the GSD aims to allow community collaboration, allowing data from multiple sources to be collated and curated, and to provide both machine-readable and human-readable data to a variety of end-users (technical, non-technical, the press, etc.). Essentially, all the community effort that went into cataloging, fixing, writing scanners and more for CVE-2021-44228 needs to be recognized and placed in a single discoverable location, where anyone can contribute and help everyone else.
Read the next blog in this series, How we ended up with #log4shell aka CVE-2021-44228, to learn more about the issues that led to #log4shell.
Share this content on your favorite social network today!



Unlock Cloud Security Insights
Subscribe to our newsletter for the latest expert trends and updates
Related Articles:
AI Security Asymmetry: Why Speed Alone Won't Save Defenders
Published: 07/03/2026

Validating LLM-Generated Control Mappings Beyond Aggregate Accuracy
Published: 07/02/2026

AI-Speed Risk Requires Identity-Defined Reachability
Published: 07/02/2026

Proof is the Application Security Bottleneck
Published: 07/01/2026