Google Workspace - Log Insights to Your Threat Hunt
Published 08/16/2022
 Originally published by Mitiga here.
Originally published by Mitiga here.
Written by Ariel Szarf and Lionel Saposnik, Mitiga.
Google Workspace is a popular service for document collaboration for organizations and for individual users. Threat actors note that the popularity of this service has increased and search for ways to exploit vulnerabilities and misconfigurations, so it is important to know how to hunt for threats in Google Workspace.
In this article, our primary hypothesis centers on data exfiltration from Google Drive, so we searched for activities that might indicate data exfiltration in different ways, such as downloading a massive number of files, sharing files, by leveraging third-party applications, and more.
Things you may not know about Google Workspace
It’s a challenge to investigate the logs
Unfortunately, there is critical data that is missing when you look at the log data. The top forensic data that is (surprisingly) not included in the fields of the log include:
- User Agent - It’s common in cyber investigations to use user agent to map devices and applications and rely on these insights to go deeper. In the Google Workspace logs, there is no mention of user agent. Hence, all we have for this type of data is IP addresses, so we worked hard to create useful insights from IP addresses only.
- Paths - For each action performed on a file, the parameters field contains doc_id, doc_type, and doc_title. But where is the path? We needed to find a way to get this information, and we did! It is described below.
- Anonymous access - Surprisingly, when an anonymous user accesses a file that is shared to the public using the people_with_link permissions, there is no log entry about it.
In addition, one of the main challenges we encountered was inconsistency of IPs per user in a short time-frame. We enrich the data with MaxMind and others to find VPNs and things like that, but even after this, there is still a lot of inconsistency in the data. It’s mainly because of the activity of third-party applications. We will elaborate on these challenges in the third-party application section.
In general, after taking the steps we discuss in this post, the Google Workspace logs are suitable for investigation.
Facilitating log readability
Parameters Representation
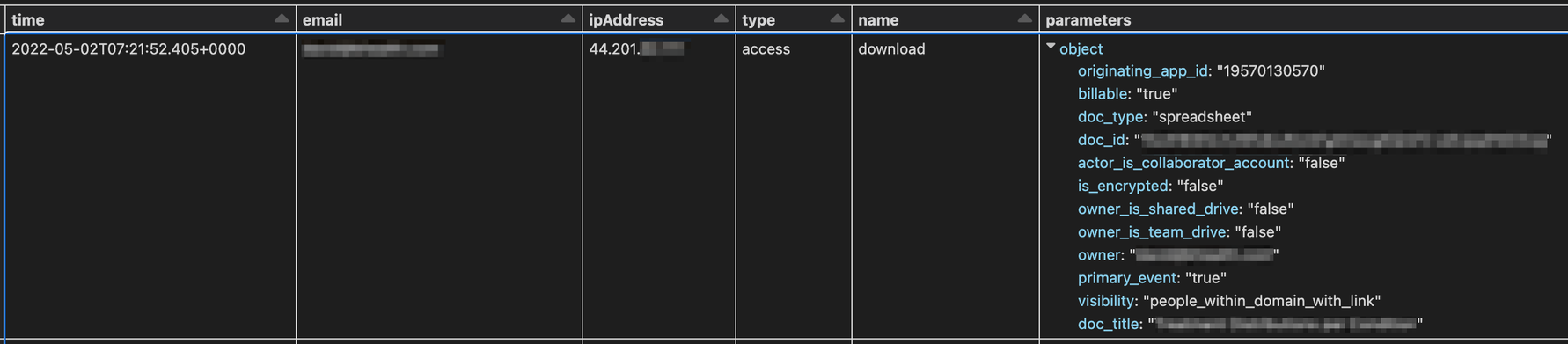
Under event[*].parameters there is list of dictionaries that represent the parameters. For example, for download event, there is the following list of parameters:
[
{"boolValue": true, "intValue": null, "multiValue": null, "name": "primary_event", "value": null},
{"boolValue": null, "intValue": null, "multiValue": null, "name": "billable", "value": null},
{"boolValue": null, "intValue": null, "multiValue": null, "name": "doc_id", "value": "0123456789AbCdEf="},
{"boolValue": null, "intValue": null, "multiValue": null, "name": "doc_type", "value": "pdf"},
{"boolValue": null, "intValue": null, "multiValue": null, "name": "is_encrypted", "value": null},
{"boolValue": null, "intValue": null, "multiValue": null, "name": "doc_title", "value": "mitiga_love_letter"},
{"boolValue": null, "intValue": null, "multiValue": null, "name": "visibility", "value": "people_with_link"},
{"boolValue": null, "intValue": null, "multiValue": null, "name": "originating_app_id", "value": "640853332981"},
{"boolValue": null, "intValue": null, "multiValue": null, "name": "actor_is_collaborator_account", "value": null},
{"boolValue": null, "intValue": null, "multiValue": null, "name": "owner", "value": "***@mitiga.io"},
{"boolValue": null, "intValue": null, "multiValue": null, "name": "owner_is_shared_drive", "value": null},
{"boolValue": null, "intValue": null, "multiValue": null, "name": "owner_is_team_drive", "value": null}
]
For each parameter, there is a specific dictionary. The name field is the trivial field, but the value field is stored in an unusual way. There are boolValue, intValue, multiValue (that is an array) and value (that is a string). The value is stored under the relevant field that represents the field type. The rest of the fields (that represent other types) are set to null.
This structure is really hard to work with, so in order to make it more readable to the investigator’s eyes, we restructured the format of the data, like this:
{
"primary_event": True,
"billable": False,
"doc_id": "0123456789AbCdEf=",
"doc_type": "pdf",
"is_encrypted": False,
"doc_title": "mitiga_love_letter",
"visibility": "people_with_link",
"originating_app_id": "640853332981",
"actor_is_collaborator_account": False,
"owner": "***@mitiga.io",
"owner_is_shared_drive": False,
"owner_is_team_drive": False
}
At Mitiga, our investigation platform uses Spark, so we highly recommend using the User-Defined Function to help with the reconstruction work.
Chains of events
Each event record in the log includes a field called events. This field contains an array, which we will describe it as “chain of events”. Every element in this array represents one sub-event. In the chain of events, there is a sub-event that is marked as the primary_event (in the parameters field). Usually, this sub-event is the operation that caused the other sub-events to happen. For example, when a user creates a file, in the log there is a chain of events under the events column that follow:
- create - the primary event
- edit
- change_document_visibility
- change_document_access_scope
- change_user_access
- change_acl_editors
- add_to_folder
For our convenience, we have split each sub-event in the events field into a dedicated log record. That way we make it more readable for the investigator. In this blog, each log record that we refer to as an event is actually a sub-event in the original log record struct.
Unique ID
Based on our definition of events in the last section, we need to redefine the unique ID per event.
There is the id.uniqueQualifier field, but Google doesn’t guarantee that one value won’t appear more than once. In the Google documentation, the definition of this field is: “Unique qualifier if multiple events have the same time.” (Here, for example: https://developers.google.com/admin-sdk/reports/reference/rest/v1/activities/list.) In other words, the combination of id.time and id.uniqueQualifier together form a unique ID.
Because we split the events field, this combination is not enough. In order to handle this, using Spark we include the posexplode function, which adds the pos column. This column contains the position in the array that appears in the original events field. The unique ID that we built is a combination of id.uniqueQualifier, id.time, and pos.
Actions by third-party applications
Events in the Google Workspace audit log might include a field called originating_app_id. This ID represents the application that performed the operation (on behalf of a user). Applications can be SaaS solutions (such as Slack, Monday, and so on) and can be an endpoint application running on the user's device (for example, the Google Drive app, Google Chrome). Be aware that applications can be third party and not only first party apps.
With the help of AppTotal, we were able to match between the IDs and the applications. AppTotal provides details on the application, including name, publisher, required permissions, and in some occasions it also includes a partial list of known IP addresses and more information.
It was super relevant for our investigation in two aspects:
- When we investigated the IPs, we found a lot of users that appear in two or more different countries on the same day. Then we realized that applications might perform operations from the IP addresses of hosting providers. Following that, we filtered out operations that include the originating_app_id field. Then we found just a few anomalies, so we could dive deep down into each one of them.
- We also investigated applications in our effort to identify compromised users. In other words, this field enabled us to search for malicious or compromised applications. In our hunt, we analyzed the data through two prisms: users and applications.
Example of originating_app_id:
In this example, the application is Slack.
The IP is under 44.192.0.0/11, which appears here: https://ip-ranges.amazonaws.com/ip-ranges.json as an EC2 service subnet. This IP is located in the United States according to the IP’s geo-location, but this user actually lives and works in other country.
Data exfiltration use cases
There are many ways to exfiltrate data from Google Drive. For example, these events (in events[*].name) can be performed to exfiltrate data:
- download
- email_as_attachment
- preview
- view
Finding those type of events and searching for anomalies, such as a massive amount of events in a short period of time, can be easily done.
Besides that, we found that it is not simple to evaluate the visibility of sharing files, so we are going to shed some light on that.
Sharing files
Visibility and access scope changes
When a user changes the access permissions by sharing a certain file using a link, there are four events that are generated: two for change_document_visibility, and two for change_document_access_scope.
First, the visibility of the document is changed to the private state and the access scope is changed to none. Afterwards, the visibility and access scope are changed to the requested state.

In the figure above, we can see the change of permissions of a certain file, from people within the organization with a link to anyone with a link.
In other cases, files can be shared a file with certain people by email address. Those people might be external to the organization.
1. In the chain of events, there are multiple event types that indicate whether a file is being shared externally to the organization.
a. The event name of change_document_visibility indicates that the parameters.visibility_change field is set to be externally. (Refer to it in Google’s documentation: https://developers.google.com/admin-sdk/reports/v1/appendix/activity/drive#change_user_access.)
Note: If the organization owns multiple domains, the primary domain set as the Google Workspace tenant is considered as the internal domain and the others are considered external.
b. The target_domain field in parameters indicates that the link allows access to other external domains if the domain is not the primary domain of the organization.
c. Otherwise, if the value is set to all, it correlates to the visibility parameter indicating people_with_link, which means that the file was shared to anyone with a link.

Sharing a file to anyone with the link.
2. When there is an acl_change event, we can see there is a correlation between the value and visibility fields in parameters:
a. Events of change_document_visibility change the visibility from people_within_domain_with_link to people_with_link. This means that the file can be accessed by anyone on the internet with the link (whether they are authenticated with Google or not).
b. We can see that change is also reflected on the values of old_value and new_value. From an old value of private it turns into a new value of people_with_link.
Mentioning a user in document
One of the method to exfiltrate data we have tested is mentioning an external user over certain marked text (such as an IT tutorial that includes a password). We assumed that when doing this, an email to the mentioned user will be sent including that text, thereby exfiltrating dedicated data with only small portion of text. After testing this type of attack, we concluded that the text is not sent to the user and a sharing approval process happens instead.
When you mention a user with @ in the document body or in a comment, if this user doesn’t have permissions to the document, a pop up displays:

If you click “Share”, there is another pop up:

This event appears in the logs as part of a chain of events that includes:
- 0 - {type:access, name:edit}
- 1 - {type:acl_change, name:change_user_access}
Surprisingly, the second event is the primary event in this chain!
An example for the parameters of these events:

Permission changes - file VS folder
In our hunt, we were interested in a scenario of a threat actor that shares a large amount of files (publicly or to a certain user who is external to the organization). One of the methods is sharing a folder that contains a lot of files and folders (this is known as “hierarchic sharing”). We wanted to separate this type of scenario from a scenario where a threat actor chose dedicated files to be shared.
When a user changes permissions for a file, there is one event type of change_user_access.
Alternatively, when a user changes permissions for a folder that contains files and folders, we observed a different behavior:
- There is a one change_user_access event on the folder (parameters.doc_type: "folder"), such that actor.email is the user email and actor.key equal to null.
- After the event above, for each file or sub folder there will be a change_user_access_hierarchy_reconciled event with actor.email equal to null and actor.key equal to SYSTEM.
Note: All of those events are primary events.
(There are more events that relate to change permissions, but they are triggered by other actions - such as edit or create a file. Our detailed explanation here is exclusively about explicit change permissions.)
Downloaded 15,000 files in a short time… and nobody noticed
In one of our hunt projects, we investigated a potential data exfiltration incident in Google Drive. We identified this activity based on the user behavior of someone who downloaded thousands of files at the same second using a private Gmail account.

As part of the investigation, we wanted to validate how malicious those actions were, based on the name and the location those files were downloaded from. As we described above, the log includes doc_id and doc_title but doesn’t indicate the path where this file originated in Google Drive. To start with, we wanted to use the data from the log in order to determine the location of the file.
We found that when creating a file in Google Drive, the log indicates the file was created and then moved to a certain folder with the add_to_folder event name. In this type of event, the destination_folder_id and destination_folder_title in the parameters field indicates the parent folder in which this file is going to be located. And as you already know, the doc_id and doc_title indicate which file is being moved.

Based on that, we created a table with the source and destination, indicating which file or folder is located in each folder. Afterwards, we used that table to recursively manipulate the logs in order to construct the path of each file.
Note: Depending on the log timeframe, the path might be partial.

After we constructed the path of each file in the logs, we successfully determined that the massive download was from a personal backup folder that the organizational user uploaded a few days before.
While the activity looks suspicious at first, it was proven not to be malicious based on our further investigation and the validation with the client.
Using the Google Workspace API
We could get the path of files in Google Drive using the Google Workspace API and get the list of IDs of the parent folders. The disadvantage of using this method is the speed of covering a large quantity of files. As we mentioned in this blog, we use Spark, which is a strong data processing infrastructure. If we keep our processing work on data only and avoid having to perform API requests, it will have less impact on our processing time.
Also, using the logs as a data source can help us investigate a state in the past, while the API can only get the current status. If the file was moved between the time of the event and the time we execute the API request, then the result from the API will not be as accurate as using the state in the past.
An interesting idea can be combining the two approaches 🤔.
Note: Querying the metadata for these files requires access and excessive permissions to be able to query all files. If the user who performs the API request doesn’t have permissions to the shared drive, My Drive, folder or file, the result will be a 404 or 403 error.
We found tools and answers that can help with querying file metadata:
Share this content on your favorite social network today!
.png)

.png)
Unlock Cloud Security Insights
Subscribe to our newsletter for the latest expert trends and updates
Related Articles:

Top 6 Claude Cowork Security Risks to Watch
Published: 07/08/2026

How to Secure AI and Find the Gaps in Your Security Operations
Published: 07/07/2026
AI Security Asymmetry: Why Speed Alone Won't Save Defenders
Published: 07/03/2026

Validating LLM-Generated Control Mappings Beyond Aggregate Accuracy
Published: 07/02/2026