Cryptominer Detection: A Machine Learning Approach
Published 09/15/2022
 Originally published by Sysdig here.
Originally published by Sysdig here.
Written by Flavio Mutti, Sysdig.
Cryptominers are one of the main cloud threats today. Miner attacks are low risk, low effort, and high reward for a financially motivated attacker. Moreover, this kind of malware can pass unnoticed because, with proper evasive techniques, they may not disrupt a company’s business operations. Given all the possible elusive strategies, detecting cryptominers is a complex task, but machine learning could help to develop a robust detection algorithm. However, being able to assess the model performance in a reliable way is paramount.
It is not so uncommon to read about the model accuracy, but:
- How far can we trust that measure?
- Is it the best metric available or should we ask for more relevant performance metrics, such as precision or recall?
- Under which circumstances has this measure been estimated?
- Do we have a confidence interval that sets the lower and upper bounds of those estimations?
Often, machine learning models are seen as magic boxes that return probabilities or classes without a clear explanation of why decisions are taken and if they are reliable, at least statistically.
In this article, we try to answer some common questions and share our experience on how we trained and assessed the model performance of our cryptominer detection model.
Problem definition
The problem that we want to address is how to detect cryptominer processes in running containers. To overcome the disadvantages of static approaches, we decided to focus our attention on runtime analysis. Each process running in a container generates a stream of events and actions (such as syscalls) that we are able to collect with the Sysdig agent. These events are aggregated, pre-processed, and near real-time classified by our backend.
From a data science perspective, the problem has been modeled as a binary classification task addressed with supervised learning techniques. However, relying on a binary result is usually not enough, especially when assessing models applied to highly imbalanced problems. In other words, the amount of data that corresponds to malicious behavior is much smaller than the usual data (e.g., miner detection).
Data collection and feature extraction
As mentioned above, each process generates a stream of low level events that are captured by the Sysdig agent. These events could be syscalls, network connections, open files, directories, libraries, and others. For a given time interval (e.g., 10 minutes), we aggregate the events and generate a raw sample of process events.
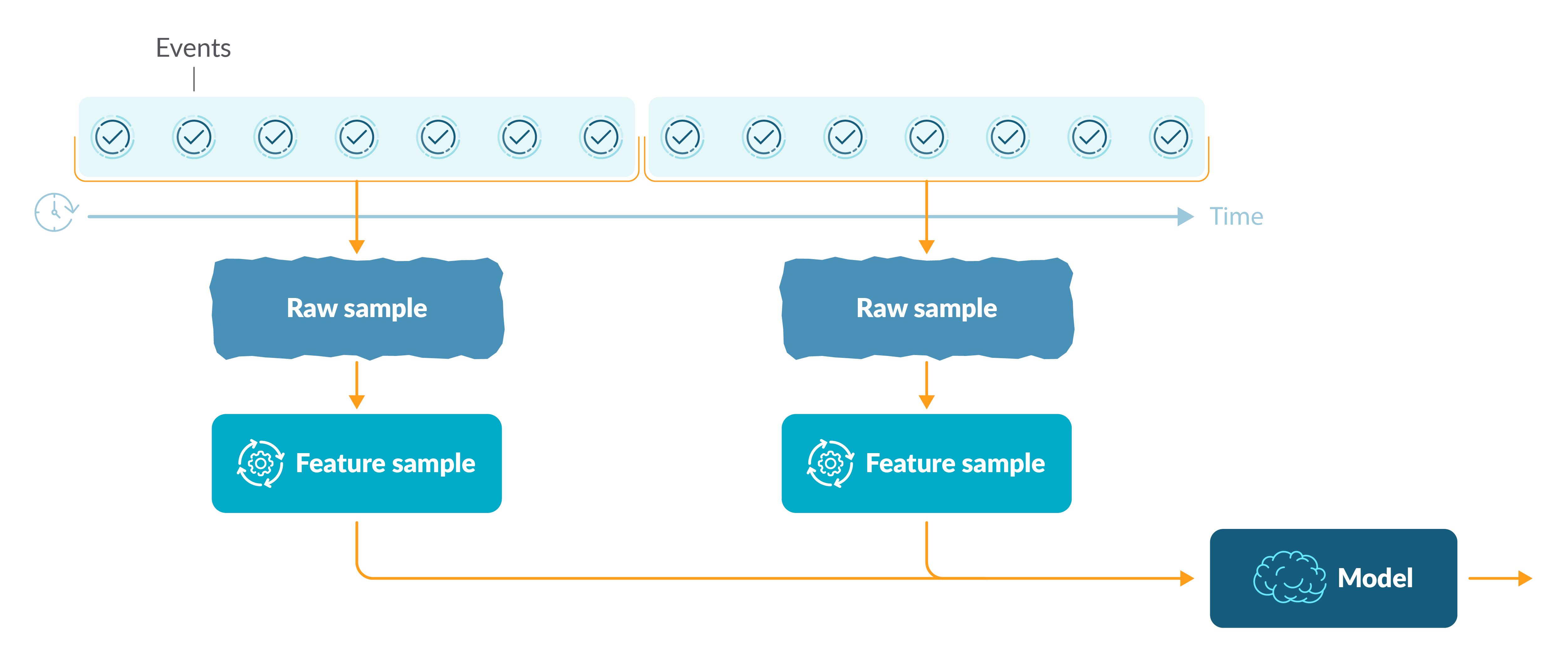
The raw sample is further analyzed and some relevant features are extracted. These features represent the domain knowledge on how cryptominers work. At the end of this feature extraction step, we have collected a sample of features that is ready to be classified by the machine learning model.
We collected two classes of data: cryptominer data and benign data from a different set of legitimate binaries:
- Cryptominer data was collected by the Sysdig Threat Research team: we had set up a honeypot and analyzed real-world malicious cryptominers.
- Benign data: we collected it by running a set of legitimate processes in common operational conditions.
One of the biggest challenges is to obtain a comprehensive and heterogeneous collection of legitimate processes to improve the performance and generalization of the machine learning model. Indeed, the fair space of processes is virtually infinite if considering that any user can potentially run anything in the cluster.
To overcome this problem we specifically designed the feature extraction process to highlight the main characteristics of cryptominers, while generalizing the legitimate ones as much as possible. We applied extensive data driven analysis on a large number of cryptominers and legitimate processes, introducing our domain knowledge in the design of the data pipeline.
Model assessment
Detecting cryptominer activities, exploiting data-driven techniques, requires a deep investigation of the scientific literature. This task brings two main challenges:
- Highly imbalanced training samples.
- High risk of a large number of False Positive detections.
We did an initial comparison between two different classes of model: classical supervised learning algorithms (such as random forest or SVM) and one-class algorithms (such as isolation forest or one class-SVM).
For model comparison, we focused on the quantitative analysis of the precision and the recall, with a qualitative assessment of the Precision-Recall Curve (PR-curve).
Qualitatively, we chose to focus on classical supervised models because one class model did not provide high performance with the initial available data.
Once we decided to further investigate supervised learning models, we ran a repeated nested stratified group cross validation on the training dataset, and computed the confidence interval for both precision and recall. We also exploited the nested cross validation to run a model hyperparameters optimization algorithm to pick the best parameters: like choosing the optimal number of engineers for increasing project successes (e.g., technically, a hyperparameter for Random Forest could be the number of trees in the forest, for a Decision Tree it could be the maximum depth). Cross validation folds contain groups of program samples: all samples from a program are contained in a single fold and there is no leak of information in other folds, in order to estimate a more realistic generalization error.
For our specific task, we decided to pay more attention to precision because, roughly speaking, we want to avoid too many false positives that lead to noise issues in the triage of security events.
Final performance evaluation
Model assessment provides an unbiased estimation of the generalization error, but we still have some main challenges to consider.
The performance on a holdout testing dataset
The holdout dataset must be representative of the underlying data distribution and this could change in time (i.e., the dataset we collect today could not be representative of the data distribution in six months).
Moreover, we continuously verify that there is no information leakage between the training dataset and the testing dataset.
The choice of the decision threshold
The choice of the threshold has been driven by the tradeoff of minimizing the false positive while managing recall (false negatives).
We decided an optimal threshold by quantitative analysis but, from a product perspective, we decided to give the customer the possibility to further tune the threshold, starting from our suggested value.
The reliability of testing performances with respect to real-word performances
The reliability of testing performances with real-world performances represent a crucial issue that we addressed by a post-deployment analysis of the model performances. And this is connected to the concept drift, where we monitor the model performance and try to detect changes over time.
The model concept drift
After having trained and optimized different models, we computed the final performance metrics on the holdout testing dataset and chose the optimal decision threshold (which is a probability chosen by an analysis of the PR curve). Then, we performed a statistical test comparing the distribution of class probabilities of different models.
The release candidate model (rc-model) is then silently deployed on the side of the model, which is currently running in production in order to compare performances. After a set period of observations, if we notice that the rc-model is statistically performing better, we substitute the current model in production with the rc-model.
Conclusion
Detecting cryptominers is a challenging task and, in order to achieve this, we explored the feasibility of applying machine learning techniques.
The first challenge was to choose how to model the problem. After evaluating pros and cons, we decided to use a supervised learning approach.
Secondly, we collected a dataset that was meaningful for the detection and explored features that were truly representative of the miner’s underlying activities. This data is coming from:
- Miners available on Github/DockerHub.
- Malicious miners deployed by most common malwares in our honeypot.
- Legitimate programs.
Third, we defined a model assessment procedure, based on nested cross validation and hyperparameter optimization. In this way, we provided the best available unbiased estimation of the generalization error.
Finally, we developed the machine learning engineering pipeline to actually run the model in production, and thanks to the collected analytics we were able to quickly iterate over several model improvements (from bugs to new data).
Share this content on your favorite social network today!
.png)

.png)
Unlock Cloud Security Insights
Subscribe to our newsletter for the latest expert trends and updates
Related Articles:

Quantum Computing & AI: When AI Starts Writing Quantum Code
Published: 07/10/2026

Governing Non-Human Identities in Agentic Systems
Published: 07/08/2026

Top 6 Claude Cowork Security Risks to Watch
Published: 07/08/2026

How to Secure AI and Find the Gaps in Your Security Operations
Published: 07/07/2026