Versioning in Cloud Environments: How it Can Cause Shadow Data & How to Mitigate the Risk
Published 06/20/2023
Originally published by Laminar.
Versioning in AWS S3 buckets, Azure Blob Containers and Google Cloud buckets is an extremely useful data management tool, and is even considered “best practice” when storing and managing data in the cloud. When enabled, this feature keeps multiple versions of an object in the same bucket[1], and can be used to preserve, retrieve and restore different object versions in case of unintended modification or deletion.
However, this seemingly important and useful feature also creates shadow data and if that data is sensitive, it increases the risk of that data being available for misuse. Fortunately, there are some simple and straightforward ways to mitigate the risk.
What Is Shadow Data?
Shadow data is any data that is not subject to an organization’s centralized data management framework and is usually not visible to data protection teams. For example, snapshots that are no longer relevant, forgotten backups, sensitive data log files which are then not properly encrypted or stored, and many more examples.
Unmanaged data backups inevitably occur, and it is often unintentional. In the following post we will explore how one specific feature available in cloud infrastructure can cause unintended shadow data, and the recommended ways to prevent this from happening.
How Versioning Causes Shadow Data
The main concepts of Versioning are similar across all three main cloud platforms: AWS, GCP and Azure. All platforms enable you to actively turn on the Versioning feature which then keeps multiple versions of an object in the same bucket, and can be used to preserve, retrieve and restore different object versions. If no policy is configured for the storage container that defines when the data should be permanently deleted or moved, these “previous versions” will stay indefinitely, usually out of sight of the average user.
In order to demonstrate the dangers of the unmonitored and uninformed use of Versioning, we will dive deeper into the AWS Versioning feature (which appears similarly in both GCP and Azure).
The Versioning feature in S3 buckets needs to actively be turned on for use. When turning on the versioning option on S3 buckets, each object in the bucket is given a VersionId. From then on, each modification/deletion gives the object a new VersionId, and the previous version is saved “behind the scenes”. The noncurrent version appears only if you perform a versioned listing[2]: it does not appear in normal listing commands, nor by default in the UI.
When an object is deleted, a “delete marker” is then inserted—the object is not actually removed, but again, moved “behind the scenes”—and can easily be restored. As depicted in Figure 1, the “delete” action does not explicitly warn that the object will not actually be deleted and does not offer the option to “permanently delete”[3]
- Bucket – for simplicity will refer to the different object storage containers available across GCP, Azure and AWS.
- Using the list-object-versions command.
- This is only offered through the UI when enabling the “show versions” option and selecting a specific version. Through the CLI this is enabled by adding the version id flag.
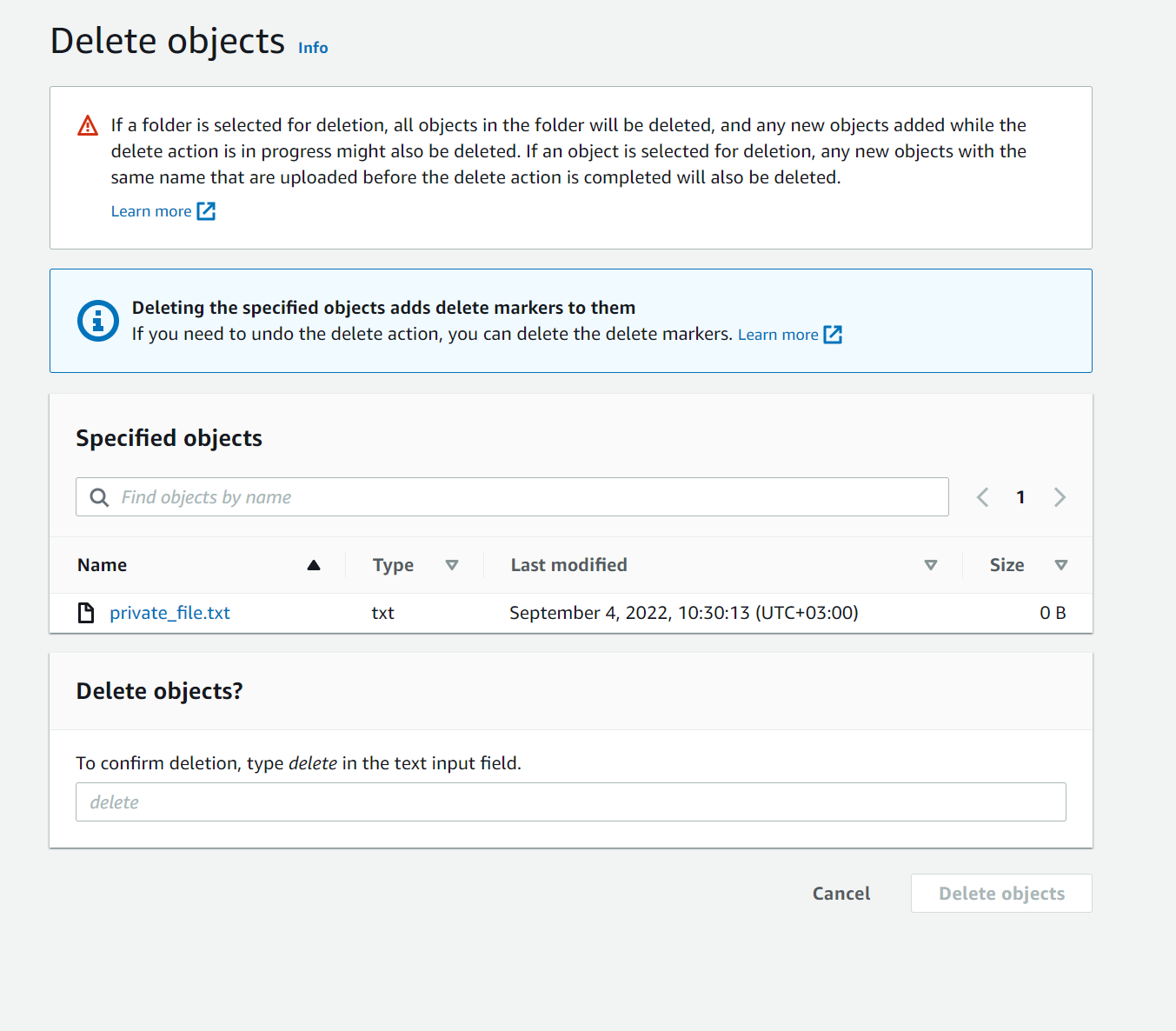
Figure 1 – Deleting an object with versioning enabled
After deletion, the bucket appears to be empty (Figure 2), but in reality it still contains the deleted files.
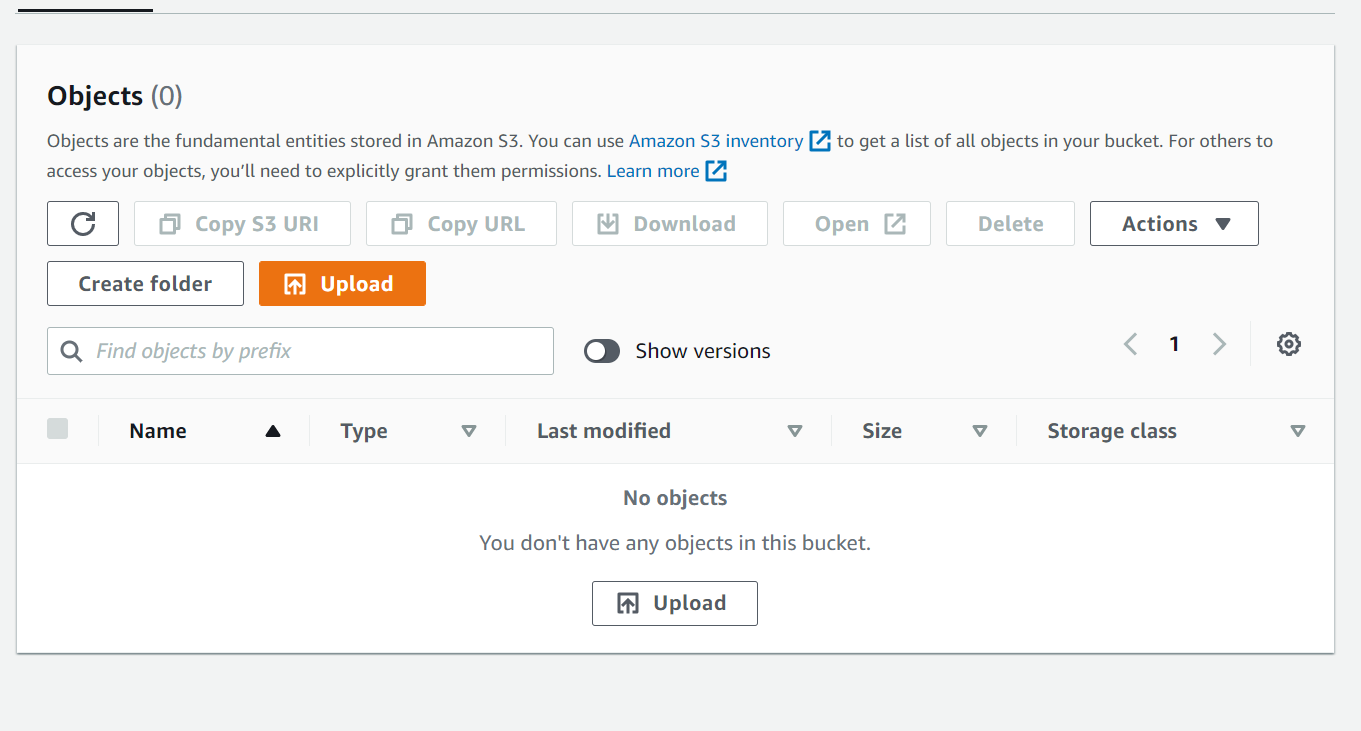
Figure 2 – the bucket after the file deletion- without “show versions” selected
You can easily see that the supposedly deleted files still remain by clicking on the “show versions” toggle switch (Figure 3).
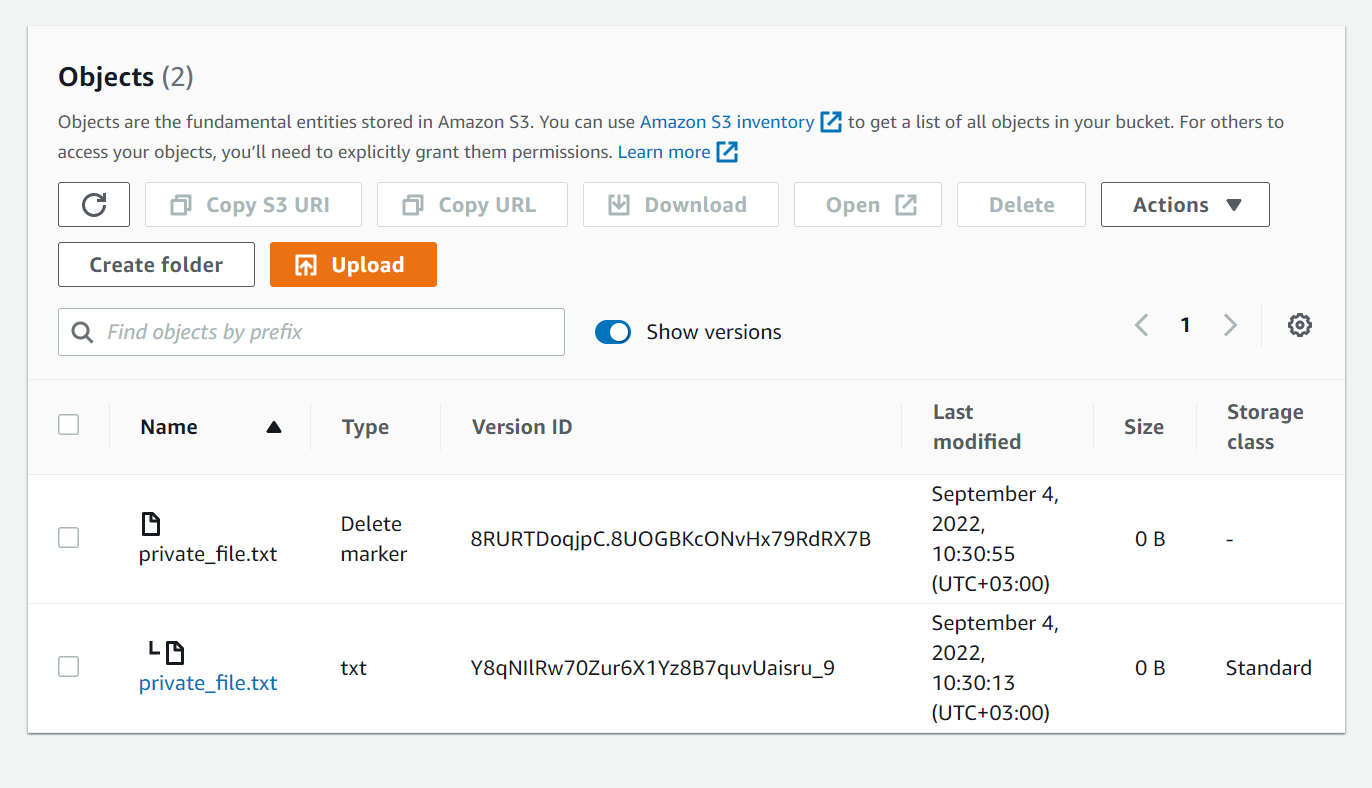
Figure 3– the bucket after the file deletion – when “show versions” is selected
Hopefully we have demonstrated this feature can easily cause accidental shadow data that has the potential to be exploited. Even if you decide to list the S3 bucket, without taking active measures to view previous versions the data is not visible to you. It is easy to actively uncover saved, noncurrent versions for one S3 bucket, but now imagine an environment with hundreds of buckets.
If that isn’t complicated enough – each previous version of an object can in certain cases inherit the permissions of the original file. While you may believe you deleted a publicly accessible file with sensitive data, if that object exists in a bucket that has Versioning enabled you may have multiple versions of objects including sensitive data which do not comply with your company policies or regulations. In order to solve this you will need to remediate the issues version by version (as each version of the object is considered a different object).In other words, you will need to go into each version of the object that is or contains sensitive public data and permanently delete them, individually.
It is also important to note that the Versioned data is data you are paying for. Although it varies slightly between cloud platforms, in general, across all three the various versions of an object are all counted as separate objects, and therefore you are charged for every version separately. Not only could you be unaware of the data itself, but you may also be paying more than you planned to.
Mitigating the Risk of Versioning
Versioning is an important tool for DevOps to limit the risk of unintended deletion or modification of important data. But given the security risks of the additional shadow data it creates it is important to take safeguards to limit the additional exposure. There are responsible and recommended ways of handling this using built-in tools – for example configuring a policy on Versioned buckets which enforces a data management policy – whether it is deleting the data after a certain amount of time or moving it to a managed storage unit. For example, AWS offers the option to configure a LifeCycle policy on Versioned buckets, which will enable safe deletion or automatically move the data to a predesignated storage bucket after a set period.
Even with a policy on Versioned buckets, it is impossible for security teams to truly be certain that this is used on all buckets in your environments. More likely than not, an organization’s environments have versioned buckets with deleted shadow data in them with no retention policy – and there is no easy and thorough built-in way of finding them.
That’s why, as part of a “trust but verify” model, it’s important to have a platform that can scan your entire cloud account and automatically detect all data stores and assets, not just the known or visible ones. Once data is scanned, the solution can categorize and classify the data, maintaining a cloud datastore framework that allows you to prioritize and manage all your assets effectively.
Having full data observability lets you understand where your shadow data stores are and who owns them. Doing so leads to a secure environment, faster, smarter decision-making across the enterprise, and the ability to thrive in a fast-moving, cloud-first world.
Share this content on your favorite social network today!

.png)
.png)



Unlock Cloud Security Insights
Subscribe to our newsletter for the latest expert trends and updates
Related Articles:
.jpeg)
How Organizations Build Mature Cloud Governance Programs
Published: 07/24/2026
.jpeg)
.jpeg)
ISO 42001: The Importance of Knowing Your Role Before Building Your AI System
Published: 07/21/2026
.jpeg)
The Hidden Risks of the Agentic Enterprise: Bridging the AI Governance Gap
Published: 07/17/2026