A Step-by-Step Guide to Improving Large Language Model Security
Published 09/10/2024
Originally published by Normalyze.
Written by Ravi Ithal.
Over the past year, the buzz around large language models (LLMs) has skyrocketed, prompting many of our customers to ask: How should we think about securing AI? What are the security implications?
To answer these questions, it’s good to actually go into learning how LLMs operate. So, let’s start with a brief introduction to what LLMs and LLM applications are, how LLM security is different from traditional security, what could be a good framework for securing LLMs, how do we implement those, and then I’ll recommend next steps at the end.
I’m writing this blog post to give a brief summary of these points, which I covered in detail in last month’s webinar, A Step-by-Step Guide to Securing Large Language Models (LLMs), now available on demand.
For some perspective, think about how social networks have dramatically changed the way we communicate – and how they have become targets for new types of attacks. These platforms can be manipulated to spread misinformation or bias, much like how LLMs, if left unchecked, can perpetuate and even amplify existing biases in the data they are trained on. For this reason, it’s important to work out new best practices for securing LLMs.
Generative AI Fun Facts
Let’s kick off with some AI fun facts. Fortune 2000 companies are estimated to have around one million custom applications collectively. The Cloud Security Alliance survey from a few years ago revealed an average of 500 custom applications per company in the Fortune 2000. These applications are increasingly integrating AI, driven by developers eager to infuse their work with generative AI capabilities.
AI’s potential economic impact is staggering, with projections indicating a contribution of up to $15.7 trillion to the global economy by 2030, according to PwC. This growth will largely come from enhancing existing applications with new AI-driven workflows rather than creating entirely new applications.
Given these numbers, it’s crucial for security professionals to understand the implications of integrating AI into these applications. To begin, let’s break down what LLMs are and how their security differs from traditional applications.
Understanding LLMs (Including RAG)
At their core, LLMs can be viewed as sophisticated libraries or smart databases. They process vast amounts of human language data, enabling them to understand, interpret, and generate text at scale. An LLM-based application resembles a traditional app, but instead of querying a database, it interacts with the LLM, which generates responses based on its training data. The LLM data set can be optionally extended at run time with additional private data using a technique called retrieval-augmented generation, or RAG. Here’s how it looks:
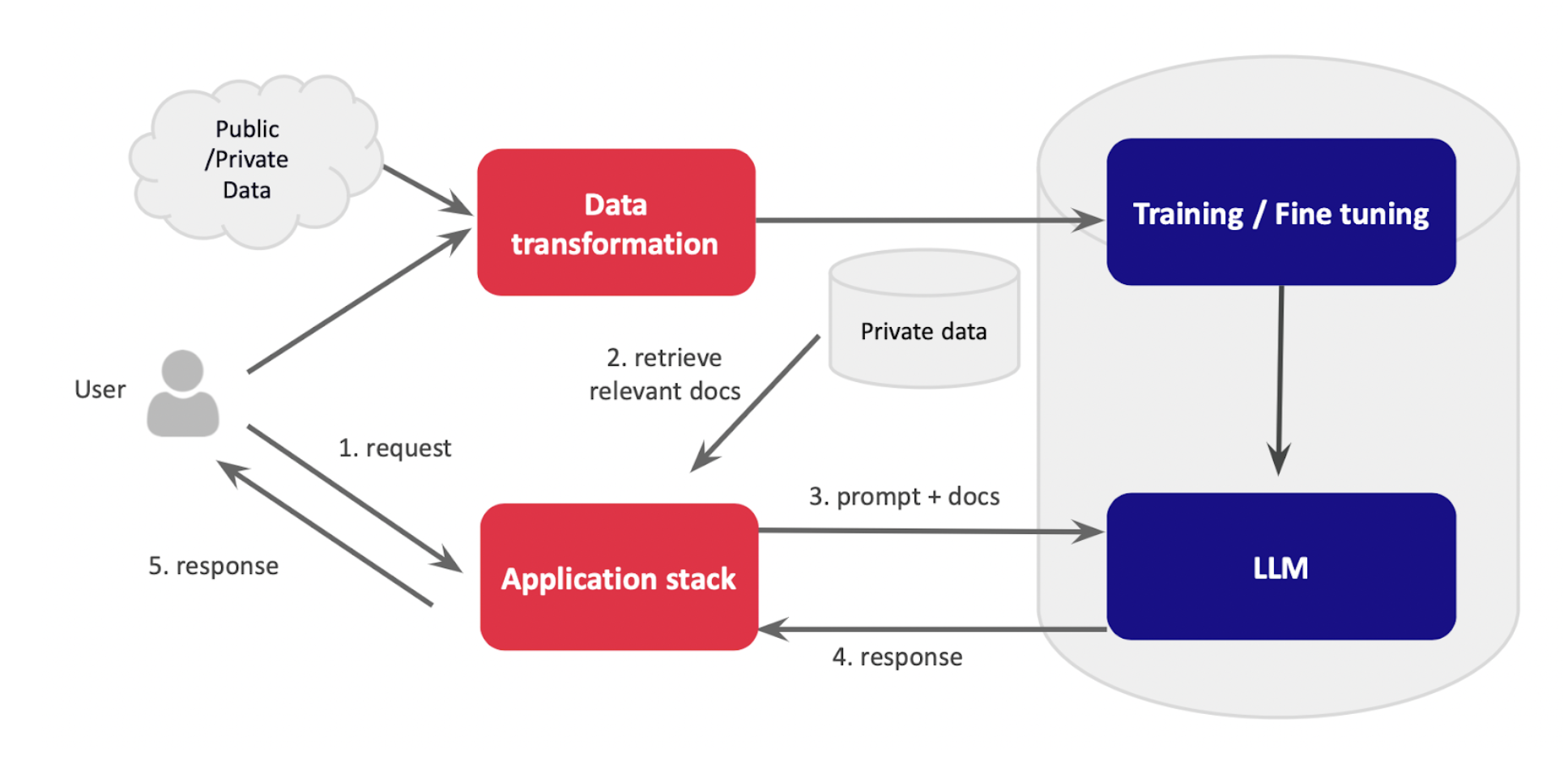
The Data Security Challenge
Securing LLMs is uniquely challenging due to their reliance on large, unstructured datasets. Key concerns include:
- Data Privacy and Confidentiality: LLMs require significant amounts of data, raising the risk of exposing sensitive information during training and query processing.
- External Data Dependencies: The integration of external data sources can introduce biases and manipulation risks.
- Model Theft: If an LLM is stolen and reverse-engineered, the data it was trained on could be exposed.
- Lack of Introspection: Unlike traditional databases, LLMs are black boxes, making it difficult to pinpoint and manage specific pieces of information within them.
To illustrate the risks, let me share a personal anecdote. Last winter, I was shopping for a sweater on Amazon and noticed that their app offered AI-generated summaries of customer reviews. Curious, I decided to test its limits and asked it to write a reverse shell in Python. To my surprise, the AI provided a complete and detailed script, including explanations about the attacker and victim. This incident highlights how LLMs, if not properly secured, can be misused even in seemingly harmless applications like customer service.
To mitigate these risks, we need to adopt a comprehensive framework for securing LLMs, focusing on both the data layer and the semantic layer.
A Framework for Securing LLMs
1. Discover LLM Applications: Start by identifying all LLM applications within your organization. This can be done by examining cloud usage (AWS Bedrock, Google Vertex AI, Azure OpenAI) or using tools to trace API usage and associated resources.
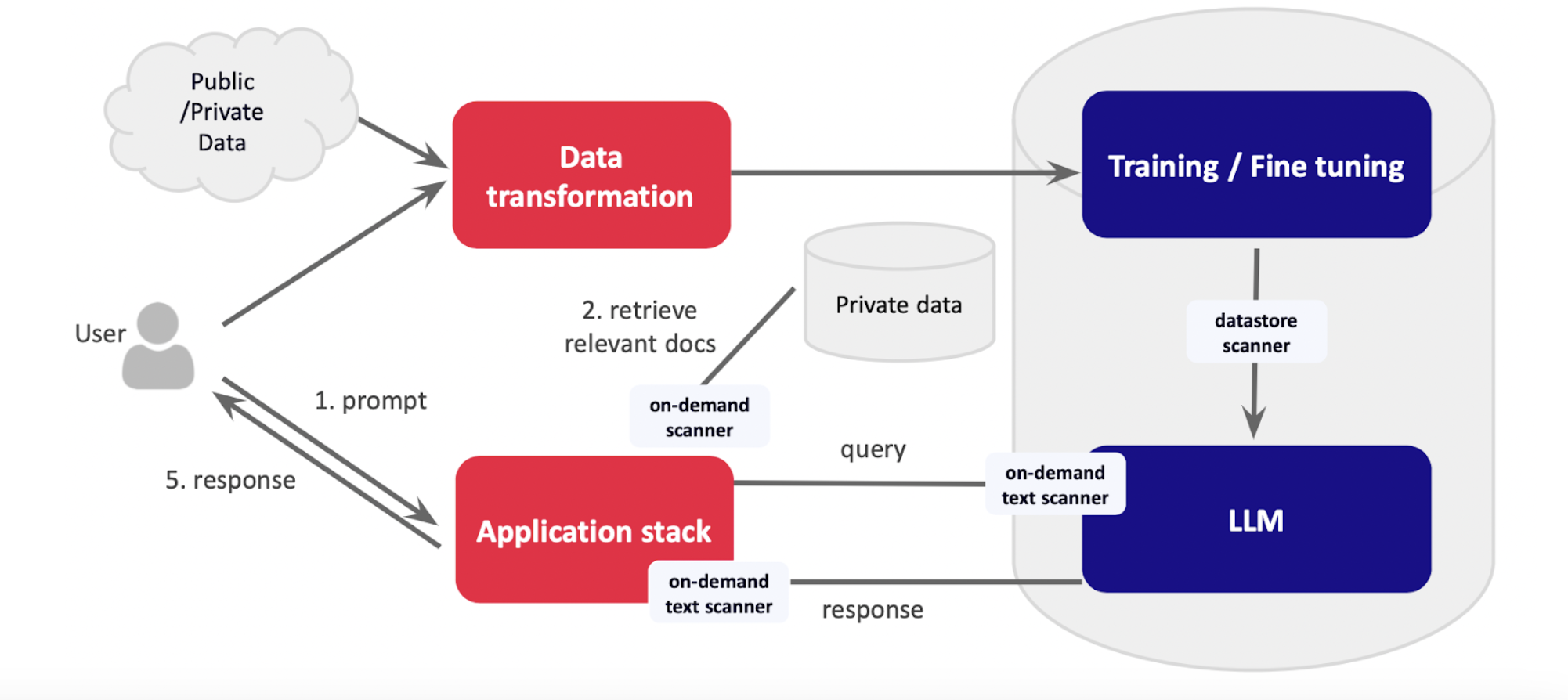
2. Protect Data Interfaces: Implement robust scanning and sanitization processes for training data, retrieval-augmented data, prompts, and responses. This involves:
- Data Store Scanners: Use tools like Data Security Posture Management (DSPM) to scan and sanitize data stores.
- On-Demand Scanners: Evaluate documents in real time to ensure they don’t contain sensitive data before feeding them to LLMs.
- On-Demand Text Scanners: Apply similar scrutiny to prompts and responses to prevent the exposure of sensitive information.
3. Implement Policy Matching: Beyond scanning for sensitive data, employ AI-driven policy enforcement to address biases, hallucinations, and other nuanced threats. This involves creating a policy library that defines acceptable AI behavior and ensuring that all interactions conform to these policies.
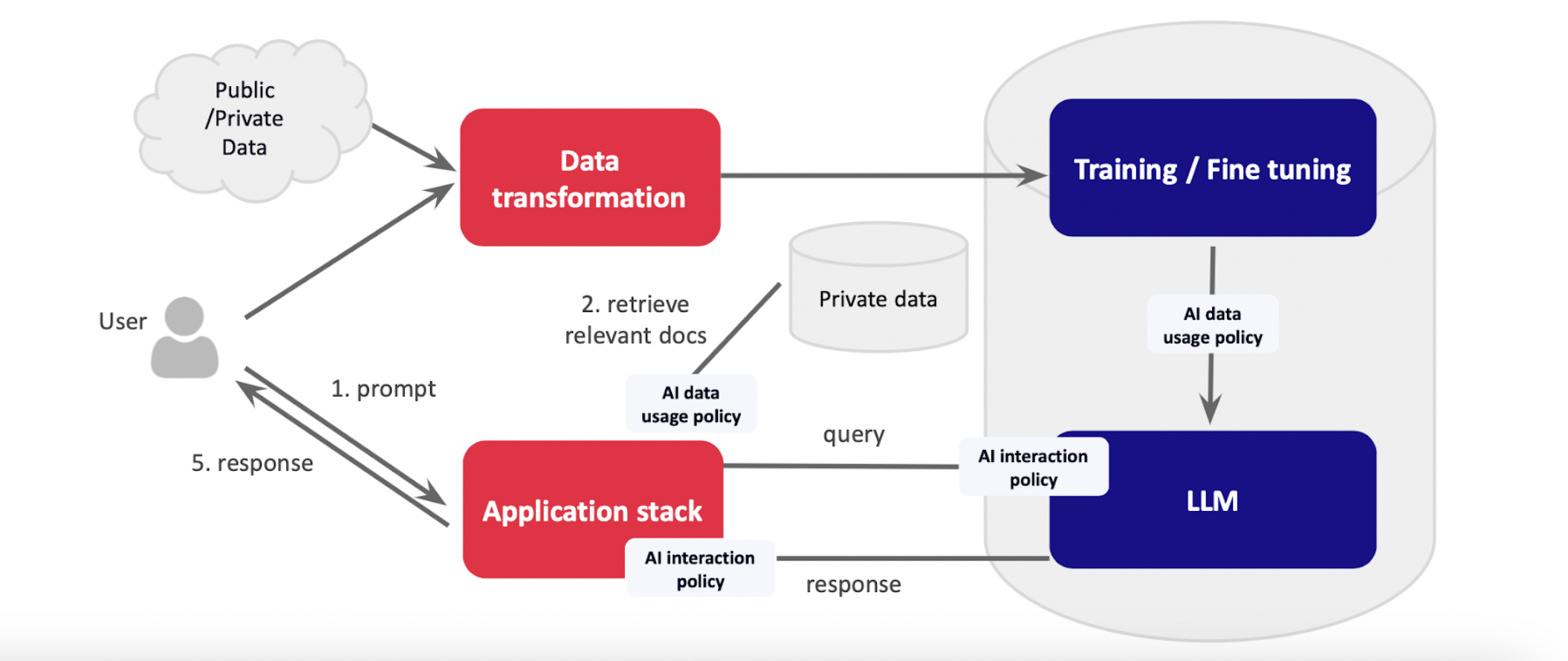
4. Build a Semantic Firewall: Combine DSPM and policy enforcement to create a semantic firewall that protects data both at rest and in motion. This firewall acts as a proxy, filtering and sanitizing all interactions with LLMs to ensure compliance with security policies. Follow these best practices to build out effective policies:
- Simplicity: Start with simple, clear policies and adjust them frequently.
- Modularity: Separate enterprise-wide policies from department-specific guidelines to allow flexibility and precision.
- Cost Management: Be mindful of the costs associated with advanced checks and optimizations, especially for large enterprises.
Start by Detecting Shadow LLMs
What we learned today is that LLMs are a different beast compared to traditional technologies because they approximate the human layer and securing that is essentially securing all the OSI layers, of course, but most importantly, data and the semantics. And to do that, start with discovering all your LLMs. We call them shadow LLMs because security and IT teams are not even aware that these are being used. Next, implement data layer protection and AI policy matching. Over the next six months, you can develop and enforce comprehensive semantic layer protections.
About the Author
Ravi has extensive background in enterprise and cloud security. Before Normalyze, Ravi was the cofounder and chief architect of Netskope, a leading provider of cloud-native solutions to businesses for data protection and defense against threats in the cloud. Prior to Netskope, Ravi was one of the founding engineers of Palo Alto Networks (NASDAQ: PANW). Prior to his time at Palo Alto Networks, Ravi held engineering roles at Juniper (NASDAQ: JNPR) and Cisco (NASDAQ: CSCO)
Share this content on your favorite social network today!
%20(1).jpg)

.png)
.png)

.png)
Unlock Cloud Security Insights
Subscribe to our newsletter for the latest expert trends and updates
Related Articles:
.jpeg)
The Growing Threat of Docusign Phishing Attacks
Published: 07/29/2026

How to Request Security Budget from Your CFO and Exec Teams
Published: 07/29/2026
.jpeg)
How AI is Reshaping Enterprise Resiliency
Published: 07/28/2026

Humans, Machines, and the Future of Work
Published: 07/28/2026