Why We Created the Global Security Database
Blog Article Published: 02/22/2022

The Global Security Database is a modern approach to a modern problem. CVE is an old approach to an old problem, one that still exists (legacy code bases), but has been superseded by new and much more complicated IT systems.
Stage 1: We can improve CVE from within
In the beginning (1999) there was CVE, and it was better than the alternatives such as Bugtraq IDs, long since dead. Back in the “good old” days if you wanted to stay abreast of security vulnerabilities, you subscribed and read Bugtraq (died in Feb 2020) and Full-Disclosure (now just a trickle of vendor advisories and malware alerts) and every vendor list that existed (not many). Finding out about vulnerabilities was difficult and tedious, and discussion of them and remediation was a real problem, aka the “which vulnerability in Sendmail are we worrying about this week?”
For the first 6 years of CVE (1999-2005), there were about a thousand vulnerability identifiers per year, in other words, CVE just covered a few things the US government really cared about (like Solaris, remember that?). It wasn’t perfect, but it was a lot better than trying to discuss vulnerabilities using the popular names of exploit code hosted on rootshell.com. But then in 2005 things changed, growth started but quickly peaked at 8000 CVEs a year and then declined until 2011.
CVE related work at Red Hat was originally led by Mark J. Cox (a current CVE board member and Apache Foundation Security Officer). In turn, Josh Bressers dealt with much of the day to day CVE effort at Red Hat, from Josh’s 2009 Red Hat Summit presentation on security):

And then in turn Kurt Seifried took over CVE related duties from Josh Bressers at Red Hat in 2011, and was even nominated to the CVE board, which he joined.
In 2011, Kurt Seifried joined Red Hat and took over CVE assignment duties there. Over a period of about 7 years, Kurt Seifried assigned over 6000 CVEs for Red Hat and then later the Distributed Weakness Filing project. During this time, Kurt successfully pushed forwards the CVE JSON format (the fifth version is now being adopted and the older data formats are being deprecated finally), and the CVE Automation Working Group has been piloting the use of GitHub for the last 4 years. Another major effort was made to federate the CVE project, more specifically to break up the flat structure of the CVE Numbering Authorities (the entities that can publish CVE identifiers into the CVE database) and create some hierarchies. For example, an OpenSource hierarchy was created underneath the Distributed Weakness Filing project in an attempt to make it easier to assign and publish CVE identifiers, especially for smaller Open Source projects.
First the good news: the growth of CVE Numbering Authorities picked up in 2015:
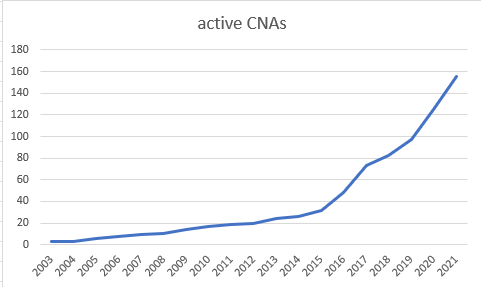
There are currently just over 200 CVE Numbering Authorities, of which one quarter have been inactive for at least a year. In other words, it’s safe to say that the proposed CVE Numbering Authorities federation never took off (if it had, we’d have thousands of CVE Numbering Authorities). In conjunction with this, while the Distributed Weakness Filing project did successfully mint a number of CVE Numbering Authorities, it never really took off. A lack of community involvement ultimately led to the dissolution of the first attempt at the Distributed Weakness Filing project.
And then there is the bad news: despite having many more CVE Numbering Authorities actively assigning CVEs, CVE assignment activity peaked in 2017 and has been largely flat, with 2020 having a spike in activity that was not sustained:
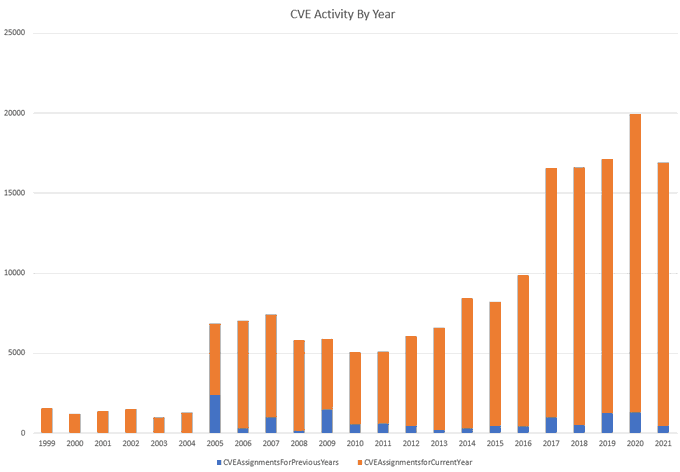
In other words, Kurt Seifried and others tried to improve CVE, bring forth new technology, expand coverage, provide better data, and all attempts have failed. The numbers don’t lie.
Stage 2: We’ll work with CVE to improve things whether they like it or not
After trying to fix CVE while working at Red Hat, both Josh Bressers and Kurt Seifried decided to try again (Josh left Red Hat in 2017, and Kurt left in 2018). It was decided that relaunching the Distributed Weakness Filing project version 2 was the way to go. The thinking was relatively simple: the DWF version 2 would simply continue to assign CVE identifiers in the million-plus number space as it had when the DWF was an accredited CNA, ensuring that there was no overlap and confusion. Please note that the DWF version 2 was not an accredited CNA like the first version was, it wasn’t actually clear at this time how CNA removal worked (or if indeed CNAs can be removed at all).
For a while things looked promising, the Linux Kernel even came on board with the Distributed Weakness Filing project. We created a partially automated integration with them in just over 48 hours and started assigning hundreds of CVEs per month for the Linux Kernel. The Linux Kernel is famous for refusing to work with the CVE Project, to quote Greg Kroah-Hartman “Kernel Recipes 2019 - CVEs are dead, long live the CVE!”
There were concerns about confusion in the CVE namespace, despite the DWF version 2 using the same million-plus numbers as it had when it was an accredited CNA. As such the DWF agreed with MITRE and stopped using the CVE designator, and started simply treating it as any other designator (e.g. OSV, GHSA, RHSA, etc.).
This turned out to be a classic blessing in disguise.
Up until mid-2021 Kurt Seifried and Josh Bressers had framed this problem as “what can we do to fix CVE?” This was entirely the wrong question.
Rather, this was the correct question, in 2011. But now we’re in 2021, and the world has changed significantly:
- Services ate the world. Most major software now includes or is entirely service-based.
- The world tried OpenSource and the world decided they liked it. Everything ships with and uses OpenSource now, including Apple, Google, Microsoft, and all cloud providers.
There’s more, but these two facts alone invalidate virtually everything the world view from 1999 that the current CVE Project is based on. Things like coverage of hardware vulnerabilities are still contentious, and coverage of services (e.g. cloud providers) is still unclear in the CVE ecosystem.
Stage 3: Global Security Database - Building for the future
So, again, Kurt Seifried and Josh Bressers sat down together (remotely, via Signal, because we live in different countries/timezones) and started discussing some ideas. One of the first things we realized is we couldn’t do this ourselves, it needed to be a much larger effort with easy onramps for people to get involved. Fixing the global vulnerability identifier space is clearly a problem that needs more than two people working on it to fix it.
It’s clearly time for something new.
The reality is that the entire IT industry has changed significantly in the last 20+ years since 1999. Here’s a shortlist of changes:
- Scope of coverage: software, hardware, services, AI/ML, Smart Contracts - most of these didn’t exist in 1999.
- Scale of coverage: Python has over 200,000 packages now. NPM has 1.3 million packages. There are numerous ecosystems and tens of millions of Open Source packages in use. To say nothing of closed source software.
- Quality of coverage: CVE-2021-33751 says “Storage Spaces Controller Elevation of Privilege Vulnerability This CVE ID is unique from CVE-2021-34460, CVE-2021-34510, CVE-2021-34512, CVE-2021-34513.”
- Ease of access to request, update and correct identifiers.
- Lack of data: CVE-2021-44228, the CVE entry text description and machine-readable data list one package, “log4j-core” from Apache Log4j as being vulnerable. However the reality is that thousands of vendors ship log4j and are affected, the CISA and NCSC-NL databases list thousands of products and versions (and this is only the tip of the iceberg).
- Lack of complementary data types: for example, the Common Weakness Enumeration database has only added 111 new types in the last 2+ years (there are still no smart contract or blockchain specific vulns at all).
- Transparency and Openness: when you request an ID or an update to an ID what happens? Does the request disappear into a closed system, or get tracked openly?
- Lack of community: where can you discuss vulnerability identifiers?
And this list is nowhere near complete.
The problem quickly becomes daunting, where do we even begin? There are also deadlocks: How do we fix data quality if we don’t have terms and words to describe the problems? How do we create new words and terms and agree on what they mean when we don’t have good data to use for research?
The good news is the solution is simple: we just start doing it, in the most classic OpenSource tradition we have setup the GlobalSecurityDatabase and started taking the first steps forwards.



Trending This Week
#1 The 5 SOC 2 Trust Services Criteria Explained
#2 What You Need to Know About the Daixin Team Ransomware Group
#3 Mitigating Security Risks in Retrieval Augmented Generation (RAG) LLM Applications
#4 Cybersecurity 101: 10 Types of Cyber Attacks to Know
#5 Detecting and Mitigating NTLM Relay Attacks Targeting Microsoft Domain Controllers
Related Articles:

Navigating the XZ Utils Vulnerability (CVE-2024-3094): A Comprehensive Guide
Published: 04/25/2024


Do You Know These 7 Terms About Cyber Threats and Vulnerabilities?
Published: 04/19/2024

10 Tips to Guide Your Cloud Email Security Strategy
Published: 04/17/2024