Zero Trust Guidance for Achieving Operational Resilience
Released: 04/06/2026

- How resilience extends beyond BC/DR to ensure continuous operation at minimum viable service levels
- Why Zero Trust is foundational to reducing risk, limiting blast radius, and enabling rapid recovery
- How to conduct a Business Impact Analysis (BIA) that aligns business priorities with security and operational decisions
- The supply chain and third-party dependencies that are critical factors in enterprise resilience
- How to implement continuous monitoring, testing, and maturity models that enable measurable resilience improvements
Download this Resource
 Best For:
Best For:
- Zero Trust Architects & Security Engineers
- Resilience Architects & BC/DR Teams
- Risk Management & GRC Professionals
- Enterprise Architects
- IT & Security Leadership (CXOs, Directors)
Introduction
Resilience is the “ability to remain viable amidst adversity,” defined within 2024 Volume 4 What is Resilience and How Does It Promote Digital Trust (ISACA). Unlike the historical principles behind disaster recovery (DR) and business continuity (BC), where organizations were offline until full operational capability was restored, resilient organizations presume incidents will happen and therefore must work to establish minimal viable service levels (MVSL). Specifically, organizations must define contingency plans to remain operational at or above our MVSLs until full capability is restored.
Zero Trust Guidance for Building a Resilient Enterprise was inspired by a 2024 CSA survey and report sponsored by the Depository Trust & Clearing Corporation (DTCC) titled, “Cyber Resiliency in the Financial Industry 2024.”
Resilience translates into measurable business outcomes—including regulatory defensibility, revenue continuity, competitive differentiation, and optimized investment. Resilience is a strategic advantage, not just a technical function.
Following established Governance, Risk Management, and Compliance (GRC) practices and the Operational Resilience Framework (ORF), we recommend the appointment of an executive accountable to senior leadership and the Board of Directors (BOD) for the organization aiming to meet its resilience objectives. This document uses the term Operational Resilience Executive, following the practice established in the ORF, described as a “qualified executive with the responsibility and authority to ensure appropriate organizational support, implementation, and oversight for operational resilience.”
This paper presumes a basic working knowledge of Zero Trust, and it aims to help practitioners achieve their resilience objectives by leveraging the principles and practices of Zero Trust. With many organizations already on a Zero Trust journey, much of the work may have already been accomplished. The incremental difference could be minimal.
The authors of this paper recognize that each organization is unique, its environment evolves, and organizational change is inevitable. While the paper is primarily for practitioners who are planning, overseeing, and doing the work, senior leadership, board members, regulators, and the like will also find value to help the organization achieve its resilience objectives.
This paper makes extensive use of authoritative sources. This paper benefits from the active engagement by thought leaders, and the authors of the authoritative sources.
This document analyzes the critical role that resilience plays in enabling organizational strength and sustained operations. Resiliency means far more than disaster recovery from operational or IT disruptions, and it extends beyond the traditional boundaries of business continuity planning. Today, resiliency has evolved into a strategic framework for strengthening the entire organization so it may reliably fulfill its purpose. Understanding this expanded role is essential, as resilience has become a key consideration in executive-level decision-making.
Importance of Resilience
Resilience is increasingly important because of the ever-growing complexity of the modern enterprise and the increasingly interconnected world within which every organization resides. Recent disruptions with Amazon Web Services (AWS), Microsoft Azure, and Cloudflare are examples. In response to this growing complexity, legislators and regulators have enacted many new laws and regulations, including the Digital Operational Resilience Act (DORA) (EU Financial), Network and Information Security Directive 2 (EU cross sector), E21, Operational Risk and Resilience (Canada), and the National Resilience Strategy (US).
The importance of resiliency is coming to the forefront for executives around the globe, as shown in articles like, “Why Boards Need to Add Strategic Resilience to the Agenda,” “The Board’s Role in Building Resilience,” and “Harnessing Collaboration to Navigate a Volatile World.”
As resiliency becomes a higher priority in business strategy and goals, it can work to:
- Provide a robust and high integrity supplier of services and products to customers as a competitive advantage
- Influence merger, acquisition, and divestiture strategies
- Make security decisions on the procurement of products and services, including third party providers
- Ensure regulatory compliance
- Oversee access to critical systems, management of policies and user identification, and privilege levels commensurate with Zero Trust best practices
- Ensure that processes are strong and improvements are continually measured
- Ensure costs are planned and comply with agreed plans
Realizing Resilience
The Business Impact Analysis (BIA) framework is used to stack rank priorities, ensure alignment, and set MVSLs to help manage complexity and ensure compliance with legislation and regulation. The outputs of the BIA become the requirements driving strategy, architecture, design, build, test, and operations.
Unlike traditional disciplines like DR, which heavily rely on technology, and BC, which relies heavily on people and process, resilience depends on an active collaboration between people, process, technology, and organizations to meet objectives. Gone are the days when we relied solely on technical controls to prevent incidents. With resilience we focus on the collaboration of people, process, and technical and organizational controls, recognizing that incidents will happen.
At its core, resilience is a new way of viewing and protecting the enterprise. The interconnected nature of the modern world compels us to consider how incidents outside our enterprise affect us and how incidents within our own perimeter impact others.
True resilience goes beyond risk identification and mitigation; it is about preparing for disruption, adapting to change, ensuring continuity of essential services, and collaborating with internal and external stakeholders to recover quickly and maintain trust. It also includes continuous monitoring for new threats, learning from incidents, and continually improving. In building resilience, we seek to identify, eliminate, or at least mitigate:
- Single Points of Failure (SPOF)
- Concentration Risk (risk aggregation)
- Counterparty Risk
- Contagion
- Cascading Risks
Resilience and the Role of Zero Trust
“The art of war teaches us to rely not on the likelihood of the enemy not coming, but on our own readiness to receive him; not on the chance of his not attacking, but rather on the fact that we have made our position unassailable.” - Sun Tzu, The Art of War
Historically, we believed as an industry we could prevent incidents by the deliberate implementation of defenses. The few that got through would easily be addressed by the technical staff or would be covered by insurance (risk transfer). We also believed technical controls were sufficient defenses. After all, it is the digital assets under attack.
That is no longer the case. Incidents happen quickly and too often. Incidents are too disruptive, taking businesses offline for days, weeks, or even months. The impact to the business is too great. Too much to be covered by insurance. The long tail can last years with resulting lawsuits and loss of digital trust lasting years. In some cases, incidents are so damaging to organizations and their supply chains that government intervention or support is required, as seen in the UK with the Jaguar Land Rover (JLR) breach.
Malicious actors understand that many years of implementing technical controls have made these technical controls our strongest defense, so they go around them by attacking the people, the process, and the organizational dimensions. Most agree attacks on the human dimension (social engineering) are key in more than 90% of incidents. Some believe the number is 98%.
What to do? The solution is simple, but difficult to execute. Instead of just focusing on technical defenses, we focus on the technology, the people, the processes, and the organizational dimensions through the entire cybersecurity lifecycle of protecting, detecting, and recovering. NIST decomposes this into the six functions: Govern, Identify, Protect, Detect, Respond, Recover in the Cybersecurity Framework (CSF). There is no material difference in principle.
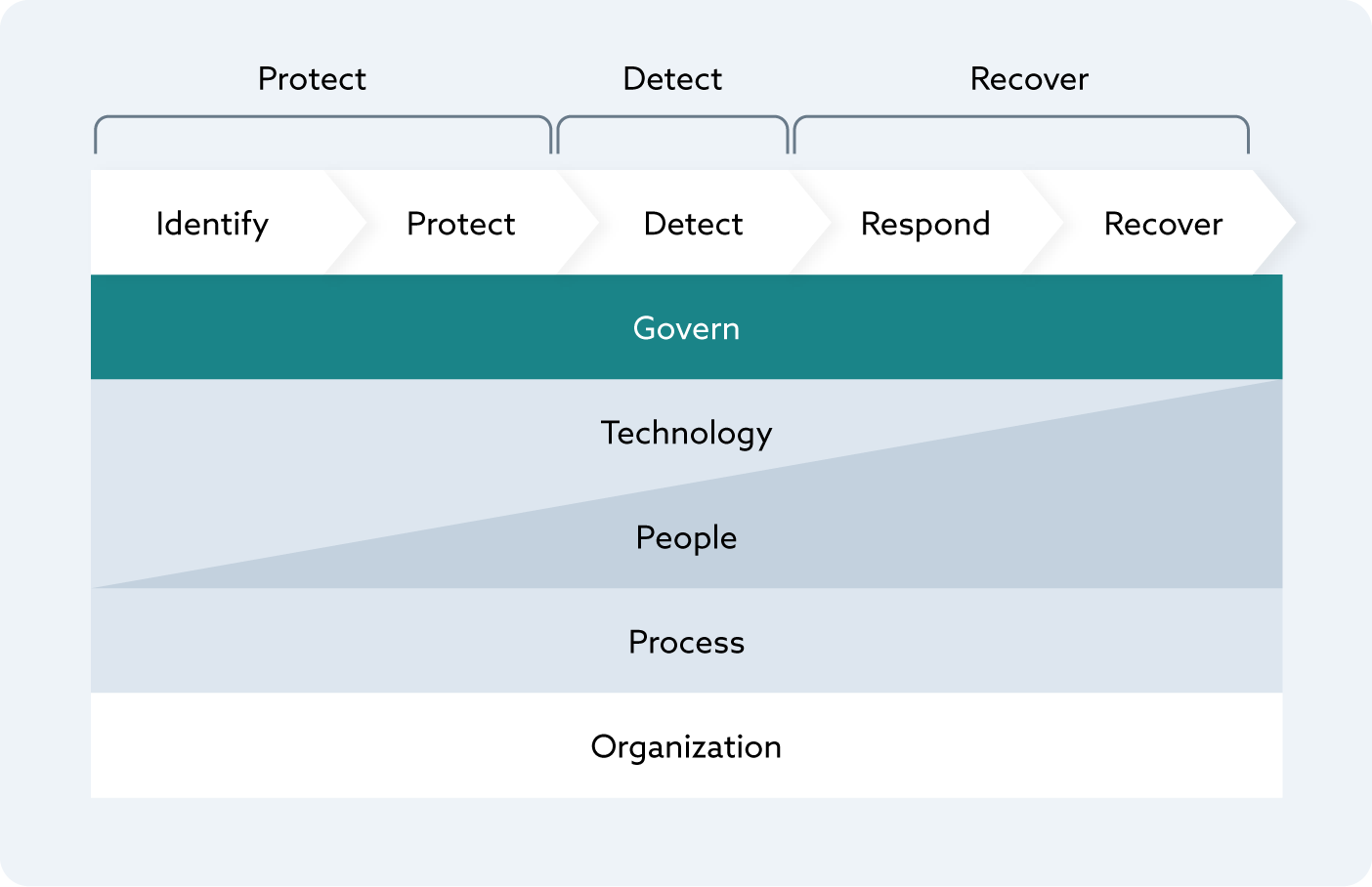 Figure 1. The Cyber Life Cycle
Figure 1. The Cyber Life Cycle
This is graphically represented in the 2024 Volume 4 What is Resilience and How Does It Promote Digital Trust (ISACA).
Resilience builds upon this in crucial ways, and no longer can we treat the delivery of products and services as either on or off like we did with BC/DR. Rather we look for ways of remaining viable amidst adversity. The military refers to this as “mission assurance.” Instead of being on or off, alive or dead, we operate above the MVSL until we can fully restore.
An easily understandable example is a municipal water supply taken offline by a cyber incident. If your objective is that no more than 10k constituents cannot be without fresh water for more than 8 hours, emergency services and hospitals cannot be without fresh water for more than 2 hours, and commercial buildings cannot be without fresh water for more than 4 hours, the MVSL may be achieved by implementing alternative strategies to remain viable until full operational capability is restored.
To remain viable, the main strategy should be supplemented by alternative strategies. Alternatives allow the organization to deliver the services but at a degraded capacity. After 2 hours, municipal water supplies may be insufficient for firefighting operations. The fire department has alternatives. They staff, train, and equip their organization to use alternative water sources (e.g., lakes, rivers) to perform hose relays and tanker operations. Hospitals have water supply contracts in place with vendors that will provide water deliveries to storage tanks on site. Cities plan to distribute bottled water to communities until municipal water is restored.
Use the Business Impact Analysis (BIA) to increase alignment between the business strategy, the security architecture, and operations. Resilience takes alignment and an understanding of dependencies. Let’s face it, nobody has unlimited resources and not all services are created equal. Identifying the high risk areas and knowing our priorities help to focus our attention and determine the best allocation of resources.
Focus on external dependencies. Our world is more interconnected than ever. We rely on Cloud Service Providers (CSP), Managed Service Providers (MSP), and Managed Security Service Providers (MSSP). Historically, our plans focused heavily on our internal systems, internal assets, and internal dependencies. To be successful, we have now expanded our plan to look at external dependencies intricately. Think about what services you cannot deliver to your customers if your CSP or SaaS provider experiences an outage. Verizon’s 2025 Data Breach Investigation Report (DBIR) shows 30% of incidents are the results of a third party. That is doubled from the previous year. Other sources, like Security Scorecard and Marsh, believe the percentage is almost twice as much.
Zero Trust is a critical part of resiliency. The guiding principles for planning, implementing, and operating Zero Trust align to the concept of resilience. These guiding principles are:
- Begin with the End in Mind (Business and Mission Objectives)
- Do Not Overcomplicate
- Products are Not the Priority
- Access is a Deliberate Act
- Inside Out, not Outside In
- Breaches Happen
- Understand Your Risk Appetite
- Ensure the Tone from the Top
- Instill a Zero Trust Culture
- Start Small and Focus on Quick Wins
- Continuously Monitor
The same principles that guide Zero Trust’s implementation also guide resilience efforts. The foundational concepts of always verifying identity and access controls are essential to building resilience. Both Zero Trust and resilience employ techniques to reduce the blast radius, thereby reducing the impact and fostering faster recovery. Both employ techniques to continuously monitor. Support at a senior level is imperative for both Zero Trust and resilience.
Resilience Definitions
“It is not the strongest of the species that survive, nor the most intelligent, but the one most responsive to change.” - Leon C. Megginson, Professor of Management and Marketing at Louisiana State University at Baton Rouge (paraphrasing Charles Darwin)
Resilience and Zero Trust presume bad things will happen and emphasize preparation. Rather than focusing all efforts to avoid bad things, our objective is to prepare for when they happen. We make it difficult for an attacker to achieve their goals after a breach by limiting the blast radius when incidents occur; preparing people, processes, and technology to respond and recover quickly; and learning from the experience to make us stronger. These concepts are reflected in the definitions from major standards bodies.
NIST SP 800-39 Managing Information Security Risk Organization, Mission, and Information System View defines resilience as “[t]he ability to prepare for and adapt to changing conditions and withstand and recover rapidly from disruption.”
Similarly, ISO defines organizational resilience in ISO/DIS 22316 Security and Resilience as “the ability of an organization to respond and adapt to change. Resilience enables organizations to anticipate and respond to threats and opportunities, arising from sudden or gradual changes in their internal and external context.”
Canada defines operational resilience as “the ability to deliver operations, especially critical operations, through disruption.”
The most complete and useful definition for the practitioner that aligns with the principals of Zero Trust is from 2024 Volume 4 What is Resilience and How Does It Promote Digital Trust (ISACA): “Simply put, resilience is about remaining viable amidst adversity and being better for it. That means aligning technology strategy with business strategy and operations. It means moving away from a strategy of continually layering controls to mitigate cyber risk to a strategy where we consider different forms of risk treatments with an eye toward a collaboration among technology, people, processes, and the organization.”
Resilience Is More than Business Continuity and Disaster Recovery
Business Continuity and Disaster Recovery (BC/DR) began when business operations were not as dependent on technology as they are today. BC/DR also began when organizations were still relatively stand-alone. Today, most organizations are highly interconnected.
Resilience extends the scope outside of the four walls of the organization to External Service Providers (ESP), vendors, and supply chains. Resilience is about the collaboration of people, process, technology, and organization across the full cyber lifecycle—protect, detect, and recover. NIST decomposes protection into two phases and recovery into two additional phases, as part of the Cybersecurity Framework (CSF).
Disaster Recovery (DR) is the recovery of IT after an incident. DR focuses on technology. Business Continuity (BC) is the recovery of the business activities after an incident. BC focuses on the people and process. DR and BC are separate activities, and BC cannot be completed until DR has restored the technology. Both DR and BC are activated after an incident and are black or white. That is to say, the technology and the business are either on or off. Resilience combines DR and BC to extend them beyond the enterprise.
Traditionally, BC/DR looks at an organization’s enterprise with little regard for the organization’s role in the ecosystem. In the world of resilience, we are attuned to how a disruption at a supplier can ripple through the ecosystem, impact us, and those we are connected to. For example, if a Cloud Service Provider (CSP) is offline, it can adversely impact our ability to deliver products and services to others. Verizon’s 2025 DBIR shows the percentage of incidents from third parties doubled from 2023 to 2024.
From the perspective of Zero Trust, resilience primarily involves prioritizing strong Identity and Access Management (IAM), followed by efforts to reduce the blast radius of a breach. It is important for us to reduce the blast radius of any incident from a third party in much the same way we use segmentation and micro-segmentation on an internal network. We cannot have an incident at a third party impact our ability to deliver products and services, and we should not negatively impact those to whom we are connected. It is incumbent on every member in an ecosystem to avoid contagion and to reduce the spread. Identifying the interconnections between components and what they rely on is critical. For example, if an application is restored but it cannot be accessed because the IdAM is offline, you cannot deliver your products and services. Large organizations often have networks dedicated to backing up systems. If that network is not online, you will not be able to recover after an incident.
How we measure success changes when it comes to resilience. Resilience prioritizes business activities and establishes acceptable levels of service through a Business Impact Analysis (BIA). (See the Role of the Business Impact Analysis (BIA) section.) With BC/DR, measurable goals like recovery point objectives (RPO), recovery time objectives (RTO), impaired state objectives, and minimal viable service levels (MVSLs) are crucial. (See the Metrics and Indicators section.) Once we know what is important and what the minimal acceptable levels are, we can identify the people, the process, the technology, and the organizational components that cooperate to provide products and services.
Cyber Resilience Maturity Models
Within the Zero Trust approach, there exist two maturity models and a resilience maturity curve. The philosophies behind each are aligned, but the mechanics are different.
-
The Global Resilience Federation’s (GRF) Resilience Maturity Model complements the Operational Resilience Framework (ORF) to assess an organization’s operational resilience progress and readiness. It provides a spreadsheet tool, aligned with NIST and ISO controls, that helps organizations understand their current operational resilience, identify gaps, and plan for improvements to minimize service disruptions during events by focusing on data recovery and service provision
-
The Cyber Resilience Capability Maturity Model (CR-CMM) helps organizations assess and improve their operational resilience. The CR-CMM is independent of legislation, regulation, standards, and frameworks. The primary goal of the CR-CMM is to provide a structured approach to assess an organization’s current cyber resilience maturity and prioritize areas for improvement
-
The Cybersecurity Capability Maturity Model (C2M2) is a framework developed by the U.S. Department of Energy (DOE) to assess and enhance an organization’s cybersecurity posture for both information technology (IT) and operational technology (OT). The model uses 356 practices across 12 domains.
Operational Resilience Framework Maturity Model
Traditional BC/DR focuses on data recovery with little regard for providing services during a disruption. The GRF Business Resilience Council (BRC) launched a multi-sector working group in 2021 to take on this challenge. The Operational Resilience Framework (ORF) was developed for organizations to withstand, recover from, and adapt to cyberattacks as well as natural and accidental disruptions. The primary goal is to reduce operational risk, minimize service disruptions, and limit systemic impacts from destructive attacks and adverse events.
The framework provides rules and implementation aids that support a company’s recovery of immutable data, while also uniquely allowing it to minimize service disruptions in the face of destructive attacks and events.
The ORF was developed to be broadly applicable and is aligned with existing controls like those from NIST and ISO. Available resources include the following:
-
ORF Rules: Overview of all components of the ORF targeted to practitioners including information on the steps, rules, terminology, implementation aids, and future activities
-
ORF Rules and Maturity Model (spreadsheet): A spreadsheet containing the ORF v2 rules and maturity model to serve as a vital tool for organizations to assess their operational resiliency progress and readiness. Also includes a mapping of ORF Rules to associated NIST 800-53 and ISO 27001 controls
-
ORF Glossary (spreadsheet): A list of common terms and definitions used within the ORF
Learn more at https://www.grf.org/orf.
Cyber Resilience Capability Maturity Model (CR-CMM)
The CR-CMM helps organizations measure, benchmark, and enhance their resilience across ten key domains. The CR-CMM is a community-driven practical tool inspired by the famous SOC-CMM and aligned with NIST SP 800-160, the MITRE Cyber Resiliency Engineering Framework, and other best-in-class frameworks (e.g., ORF, Sheltered Harbor, CTI-CMM). While being sector- and size-agnostic, the CR-CMM aligns with industry best practices and draws from widely recognized frameworks maintained by organizations such as NIST and MITRE.
The maturity levels range from initial (where resilience practices are reactive and uncoordinated) to optimized (where resilience is proactive, integrated into all aspects of system design, and supported by continuous improvement).
Achieving true cyber resilience requires a structured, measurable approach and accountable leadership to continuously drive the awareness and improvement of a cyber resilient posture. Like Zero Trust, cyber resilience is an overused term that means different things to different people—whether in the industry or among regulators. This lack of clarity makes it harder to define what true cyber resilience capabilities are and to choose the right set and scale of capabilities for an organization.
An organization’s cyber resilience efforts primarily aim to ensure the survivability of mission-critical functions before, during, or after a coordinated, destructive cyberattack. Such cyber resilience efforts must address the continuously evolving risks from advanced and unpredictable adversaries. See figure below “Cyber Resilience Officer.”
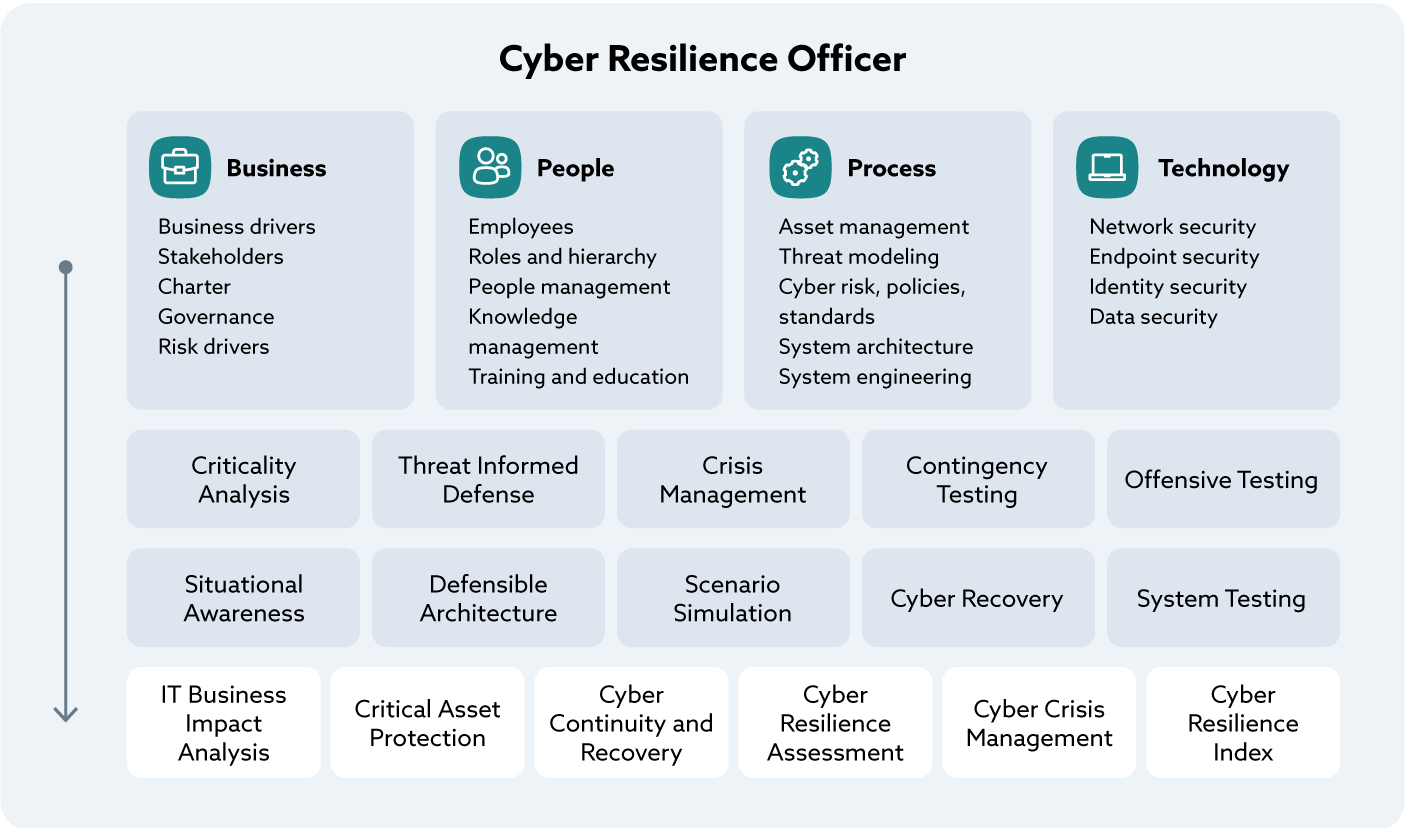 Figure 2. Cyber Resilience Officer
Figure 2. Cyber Resilience Officer
Zero Trust and CR-CMM: When “Never Trust, Always Verify” Meets “Withstand and Adapt”
CR-CMM helps organizations put strategies like Zero Trust into practice by connecting high-level principles with concrete, measurable capabilities. Take, for example, the interplay between criticality analysis, situational awareness, and defensible architecture.
A Zero Trust journey begins by asking a deceptively simple question: what matters most? Not every system or dataset requires the same level of scrutiny. Through criticality analysis, the CR-CMM guides organizations to identify which assets, applications, and processes are genuinely mission-critical. This focus ensures that protection efforts are not diluted across the entire IT estate but are directed toward the “crown jewels” that must be defended at all costs.
Once those priorities are set, resilience depends on the ability to see and interpret what is happening around them. Situational awareness provides this visibility. It equips teams with the capability to continuously monitor identities, devices, and sessions, aligning with Zero Trust’s principle that authentication and authorization must be dynamic. By embedding this practice into the maturity model, CR-CMM ensures that Zero Trust monitoring is not an isolated control but part of a broader cycle of anticipation, detection, and adaptation.
Finally, defensible architecture brings these ideas into the design of the systems themselves. Zero Trust is not simply about blocking or denying—it is about building infrastructures that can adapt under stress, limit the attacker’s freedom of movement, and preserve essential functions even in adverse conditions. CR-CMM captures this through the emphasis on layered defense, diversity of controls, and the ability to reposition resources dynamically.
Seen together, these three practices illustrate how the model transforms Zero Trust from a principle into a living strategy. By clarifying what is critical, ensuring constant awareness, and embedding resilience into architecture, the CR-CMM provides a structured pathway for organizations to uplift their cyber resilience posture in line with Zero Trust thinking.
Guiding the Cyber Resilience Officers with CR-CMM
The CR-CMM is a powerful tool for organizations seeking to strengthen their cyber resilience posture. By applying it on a regular basis (e.g., bi-annually, annually), companies are able to evaluate and benchmark their current maturity against an established baseline, gaining a clear picture of where they stand today. This understanding naturally feeds into the development of a strategic roadmap, helping leaders identify which resilience practices to enhance and how to advance maturity over time.
Beyond measurement, the model also plays a role in guiding investment and informing strategic initiatives. It helps decision-makers prioritize resources where they matter most, ensuring that each step taken contributes directly to a stronger resilience posture. Just as importantly, it creates a common language for talking about cyber resilience—one that bridges the gap between technical teams, business processes, and executive priorities.
Figure 2 entitled CR-CMM Logical Architecture illustrates how four foundational enablers (Business, People, Process, Technology) support the development of cyber resilience capabilities Together they allow a Cyber Resilience Officer team to deliver six essential resilience services to the organization at the bottom of the illustration (IT Business Impact Analysis, Critical Asset Protection, Cyber Continuity and Recover, Cyber Resilience Assessment, Cyber Crisis Management, Cyber Resilience Index).
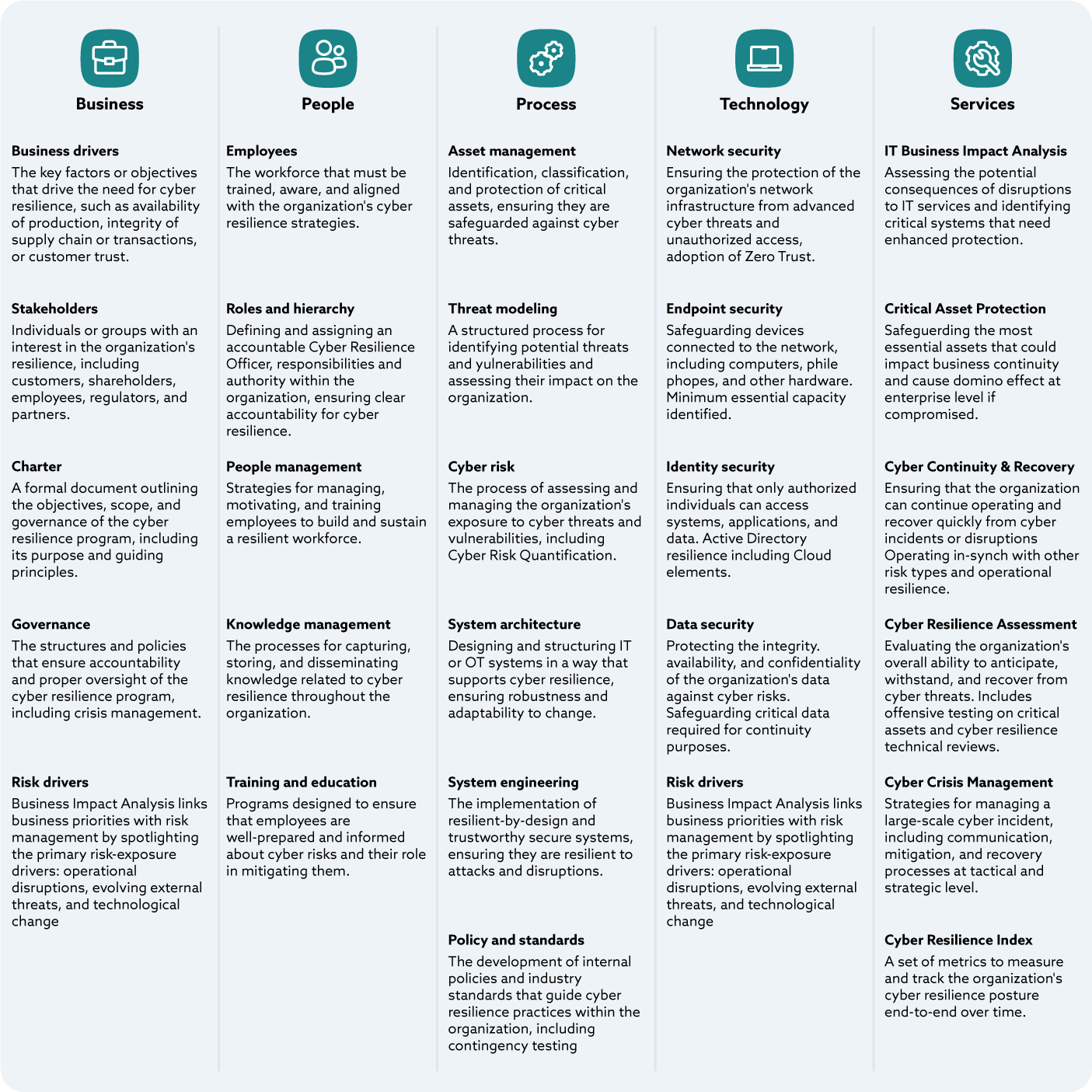 Figure 3. CR-CMM Logical Architecture
Figure 3. CR-CMM Logical Architecture
In practice, this common framework encourages collaboration across functions that often work in silos, such as cybersecurity, business continuity, IT operations, and risk management. By aligning their efforts under a unified strategy, these groups can drive more consistent and sustainable outcomes. The CR-CMM also facilitates standardized knowledge sharing between organizations, allowing them to compare progress, exchange insights, and build on shared practices. Over time, this collective approach strengthens not only individual companies but the wider ecosystem, reinforcing cyber resilience as a shared responsibility.
Learn more about the Cyber Resilience Capability Maturity Model at www.cr-cmm.org.
Cyber Resilience Maturity Curve Integrated with Zero Trust Architecture: A Framework for Financial Institutions
Cyber resilience marks an exciting evolution in security strategy. Rather than focusing on preventing every potential incident, it champions the idea of maintaining business continuity, even amidst unavoidable disruptions. Financial institutions, entrusted with vital market infrastructure and sensitive customer information, are feeling the pressure from regulators to embrace resilience-first approaches. Enter Zero Trust Architecture (ZTA) as a foundation in cyber resilience. ZTA operates on the principle of no implicit trust, inside or outside the network.
The Cyber Resilience Maturity Curve with ZTA provides a clear roadmap for financial institutions to evaluate their current security measures, plan future investments, and demonstrate compliance with regulatory standards. Each stage of the curve enhances risk management and also aligns seamlessly with established regulatory frameworks like the NIST Cybersecurity Framework, ISO/IEC 27001, and the Basel Committee’s Principles for Operational Resilience.
The Five Stages of the Maturity Curve and Compliance Relationship
1. Foundational Awareness
-
Description: Institutions are primarily reactive. Cybersecurity relies heavily on perimeter defenses with limited segmentation and ad-hoc incident handling
-
ZTA Capability: Minimal. Trust is implicit within the network, and there is no continuous verification
- Regulatory Alignment:
- NIST CSF: Identify (ID) — partial alignment through asset awareness
- ISO 27001: Control A.5.1 (Policies for information security)
- Basel Principles: Low alignment; gaps in risk management expectations
- DORA: Initial ICT risk identification (Article. 6)
2. Structured Defense
-
Description: The organization begins to formalize cybersecurity controls through standardized policies, centralized IAM, and baseline segmentation. Defensive capabilities are more consistent, but enforcement remains largely static and manual. Security is still treated as a control function, not a business resilience enabler. Cloud access is mediated through MFA and IAM, yet trust decisions do not adapt dynamically to context, behavior, or risk. Incident response and recovery planning remain siloed
-
ZTA Capability: Basic application of segmentation and authentication for privileged accounts
- Regulatory Alignment:
- NIST CSF: Protect (PR) — particularly PR.AC (Access Control) and PR.AU (Awareness and Training)
- ISO 27001: A.9 (Access control), A.10 (Cryptography)
- Basel Principles: Early demonstration of resilience planning, but largely tactical
- DORA: Protection and prevention measures (Article. 9)
3. Operational Resilience
-
Description: Cybersecurity evolves into a resilience capability aligned with business objectives. Critical business services, supporting systems, and dependencies are identified and protected. Micro-segmentation, continuous monitoring, and conditional access policies are introduced to reduce attack surfaces and limit blast radius. Analytics begin guiding policy enforcement. Decisions are increasingly guided by telemetry and analytics. Incident response and recovery processes focus on maintaining service availability rather than system-level recovery alone
-
ZTA Capability: Expanded micro-segmentation and conditional access based on identity
- Regulatory Alignment:
- NIST CSF: Detect (DE) and Respond (RS) — DE.CM (Security Continuous Monitoring), RS.MI (Mitigation)
- ISO 27001: A.12 (Operations security), A.16 (Incident management)
- Basel Principles: Principles 2–3 (Governance and operational resilience framework)
- DORA: Recovery and Response (Article. 11)
4. Integrated Assurance
-
Description: Security practices and resilience are embedded across enterprise functions, including application development, cloud platforms, third-party ecosystems, and business operations. Security controls continuously adapt based on risk signals, using automation and AI-driven analytics. Policy enforcement becomes dynamic and evidence based, supported by AI/ML for anomaly detection and automated response. Control effectiveness, not just control presence, is demonstrable. Zero Trust principles are deeply integrated into CI/CD pipelines, infrastructure-as-code, policy-as-code, and cloud-native architectures
-
ZTA Capability: Adaptive controls, real-time policy automation, automated threat isolation
- Regulatory Alignment:
- NIST CSF: Recover (RC) — RC.IM (Improvements), RC.CO (Communications)
- ISO 27001: A.14 (System acquisition, development and maintenance), A.18 (Compliance)
- Basel Principles: Principle 5 (Operational resilience embedded into business processes)
- DORA: Learning and Evolving (Article 13)
5. Adaptive Resilience
-
Description: Security is predictive and proactive. Zero Trust is fully institutionalized across all environments (on-prem, cloud, SaaS, and third-party environments), continuously validated in real-time. Stakeholders—including regulators, customers, and third parties—are integrated into the enterprise-wide model. Security and resilience decisions continuously adjust in real time based on evolving threats, business priorities, and ecosystem dependencies. Testing, validation, and assurance are continuous. Resilience metrics are shared with regulators, partners, and customers when appropriate. The organization demonstrates the ability not only to withstand disruptions but to adapt and improve through them
-
ZTA Capability: Full Zero Trust adoption. Every access request is dynamically verified; intelligent systems continuously refine defenses; security is embedded into every layer of the organization’s infrastructure
- Regulatory Alignment:
- NIST CSF: Full integration across Identify–Protect–Detect–Respond–Recover
- ISO 27001: Full enterprise-wide coverage of Annex A controls, with continuous improvement cycles
- Basel Principles: Principle 7 (Testing operational resilience), Principle 9 (Managing interconnections with third parties)
- DORA: Advanced testing of ICT tools, systems, and processes based on TLPT (Article 26)
Practical Benefits for Financial Institutions
-
Benchmarking Current State: Institutions can assess whether they remain reactive (Stages 1–2) or have progressed toward integrated resilience (Stages 3–5)
-
Targeted Investment: By mapping specific ZTA capabilities to compliance frameworks, organizations can prioritize investments that both reduce risk and satisfy regulatory audits
-
Demonstrating Compliance: Regulators increasingly expect evidence of resilience testing and maturity progression
-
Third-Party Risk Integration: Especially relevant in banking ecosystems with vendor reliance, Stages 4 and 5 demonstrate alignment with supervisory expectations on outsourcing and supply chain resilience
For financial institutions, cyber resilience is both a security imperative and a regulatory requirement. The CR Maturity Curve integrated with ZTA offers a pragmatic roadmap to strengthen defenses, align with global compliance frameworks, and sustain operations even during high-impact cyber events. Progression along the curve not only demonstrates reduced risk exposure but also positions institutions as leaders in governance, trust, and systemic stability.
Visual Representation
 Figure 4. Cyber Resilience and Zero Trust Maturity
Figure 4. Cyber Resilience and Zero Trust Maturity
Table 1 illustrates the relationship between Maturity Levels, Zero Trust Capabilities and Regulatory Alignment.
Maturity Curve with Regulatory
| Stage | Description | ZTA Capability | Regulatory Alignment |
|---|---|---|---|
| 1. Foundational Awareness | Reactive, perimeter-based, limited processes | Minimal ZTA; implicit trust | NIST CSF ID; ISO A.5.1; Basel low alignment; DORA Article 6 |
| 2. Structured Defense | Formal policies, segmentation, MFA | Basic segmentation, privileged IAM | NIST PR.AC/PR.AU; ISO A.9/A.10; Basel tactical alignment; DORA Article 9 |
| 3. Operational Resilience | Recovery, micro-segmentation, analytics | Expanded micro-segmentation, continuous verification | NIST DE.CM, RS.MI; ISO A.12/A.16; Basel governance; DORA Article 11 |
| 4. Integrated Assurance | Embedded resilience, automation, AI/ML | Adaptive controls, real-time policy automation | NIST RC.IM/RC.CO; ISO A.14/A.18; Basel integration into business processes; DORA Article 13 |
| 5. Adaptive Resilience | Predictive, proactive, full Zero Trust | Full dynamic verification, intelligent refinement | Full NIST CSF; ISO Annex A; Basel principles on testing and third-party resilience; DORA Article 26 |
Table 1.
Legislation, Regulations, Frameworks, Standards
Landscape
When it comes to resilience, there is a mosaic of legislation, regulations, frameworks, and standards. Some are focused on jurisdiction, others are sectoral, while others are horizontal across geographies and sectors. The most significant standards and frameworks include:
- ISO 22316:2017 Security and resilience—Organizational resilience—Principles and attributes
- NIST SP 800-160 Vol. 2, Revision 1, Developing Cyber-Resilient Systems: A Systems Security Engineering Approach
- Business Resilience Council (BRC), Operational Resilience Framework (ORF)
Legislation
Resilience is a key element of the U.S. National Cybersecurity Strategy issued by the White House in 2023. A series of Executive Orders (EOs), legislation, and regulations have been subsequently issued. The National Resilience Strategy was issued in 2025. Other resilience-related initiatives include:
-
The U.S. President’s Council of Advisors on Science and Technology (PCAST) is a federal advisory committee appointed by the President to augment the science and technology advice available to him from inside the White House and from the federal agencies. In February 2024, PCAST issued a report, “Strategy for Cyber-Physical Resilience: Fortifying Our Critical Infrastructure for a Digital World.” The PCAST report is driving resilience within the United States and, to a lesser extent, U.S. allies. The PCAST report is silent on use of standards while adopting many of the key elements and rules from the GRF ORF
-
Digital Operational Resilience Act (DORA) is a European Union (EU) regulation that requires financial entities to improve their operational resilience. The regulation is designed to standardize and strengthen the information and communication technology (ICT) security and operational resilience of the financial sector in the EU and serving customers in the EU. DORA imposes requirements on both the entity, their supply chain, and the infrastructure components that serve them (e.g., the cloud). DORA builds upon ISO 27001 (Information Security), ISO 3100 (Risk Management), ISO 22316 (Resilience), and ISO 22336 (Resilience implementation)
-
Network and Information Systems Directive 2022/0383 (NIS2) is an EU regulation designed to raise the cyber hygiene of entities within the EU and those that serve EU residents. Like DORA, NIS2 is not sector specific. Like DORA, NIS2 imposes obligations on the entity, their supply chain, and the infrastructure components that serve them (e.g., the cloud). NIS2 builds upon ISO 27001 (Information Security), ISO 3100 (Risk Management), ISO 22316 (Resilience), and ISO 22336 (Resilience implementation)
-
Cyber Resilience Act (CRA) is an EU regulation that supports other cyber and resilience efforts by imposing requirements on products with digital elements. CRA builds upon ISO 27001 (Information Security), ISO 3100 (Risk Management), ISO 22316 (Resilience), ISO 22336 (Resilience implementation)
-
Office of the Superintendent of Financial Institutions (OFSI), Canada Resilience (E21) is the equivalent of DORA for Canada. E21 imposes obligations on the finance sector operating in Canada or service clients in Canada. E21 builds upon ISO 27001 (Information Security), ISO 3100 (Risk Management), ISO 22316 (Resilience), ISO 22336 (Resilience implementation)
-
India’s Cybersecurity and Cyber Resilience Framework (CSCRF) for SEBI Regulated Entities (REs) is a set of standards and guidelines established by the Securities and Exchange Board of India (SEBI) to enhance cybersecurity for entities they regulate
- PRA / FCA Operational Resilience is a set of final rules and guidance on new requirements to strengthen operational resilience in the financial services sector from the Financial Conduct Authority (FCA) and the Prudential Regulation Authority (PRA)
-
European Critical Entity Resilience (CER) is a directive from the European Parliament and the Council of the European Union
- HKMA Cyber Resilience Assessment Framework (C-RAF) is part of the HKMA Cybersecurity Fortification Initiative
Control Matrices
Control matrices are important for compliance and general security. While not sufficient for achieving resilience, control matrices play a necessary role. Frameworks, like the ORF, include mappings to multiple control matrices.
The Cloud Controls Matrix (CCM) developed by the Cloud Security Alliance (CSA) contains a Business Continuity Management and Operational Resilience (BCR) domain. The BCR domain contains eleven control specifications. In addition to the controls and the implementation guidelines, the BCR domain includes vendor/service-specific Shared Security Responsibility Model (SSRM) guidance in CAIQ responses from the CSPs. Learn more about the CCM with these resources from CSA:
- CCM Video Series: BCR - Business Continuity Mgmt & Op Resilience
- NIST SP 800-53 Rev. 5 Security and Privacy Controls for Information Systems and Organizations (SP 800-53 Rev 5.2.0) was issued as a special release on August 27, 2025. Among other things, the incremental release includes a control dedicated to resilience, SA-24, “Design for Cyber Resiliency”
- Mitre Enterprise Candidate Mitigations which represent security concepts and classes of technologies that can be used to prevent a technique or sub-technique from being successfully executed
Collective Resilience
Collective resilience is the coordinated ability of organizations operating in an interdependent ecosystem (e.g., enterprises, vendors, suppliers, partners, platforms) to sustain Minimum Viable Service Levels (MVSLs) under stress, operate in predefined impaired states, and recover quickly in ways that limit systemic impact to others. Resilience is therefore an ecosystem property, not just an enterprise property—it extends beyond a single organization to the end-to-end ecosystem that actually delivers the service. Within the Operational Resilience Framework (ORF) from the Business Resilience Council (BRC), this begins by understanding your role in the ecosystem: identify and prioritize stakeholder groups, classify services (e.g., Operations-Critical, Business-Critical), and establish the targets that must be met when conditions are degraded.
Traditional collective defense concentrates on shared situational awareness and coordinated containment so each member can better prevent or limit incidents. Collective resilience becomes clearer when viewed through real-world interdependency and failures. For example, a CSP regional outage can create immediate, multi-tenant disruption, preventing numerous organizations from accessing critical SaaS platforms—even when their internal systems remain healthy. The outages experienced with Azure, AWS, and CloudFlare in late 2025 are examples.
In the software supply chain, malicious code injected into a single supplier may corrupt build pipelines or introduce compromised artifacts, affecting thousands of downstream enterprises as the malicious code is carried through the software distribution network. SolarWinds, Codecov, Log4j, MoveIT are well-known examples.
Disruption in payment ecosystems can paralyze operations across banks, merchants, and service providers, revealing how interconnected operations truly are. These scenarios highlight that resilience cannot be achieved in isolation. Resilience requires shared situational awareness, aligned expectations, and coordinated recovery mechanisms across the wider ecosystem.
Collective resilience is the next step—turning shared defense into shared delivery. Parties work together to ensure Operations-Critical services continue through a crisis, even when one or more participants are impaired. The emphasis shifts from only detecting and blocking to assuring service outcomes across organizations. A key consideration for this is ensuring that communication between organizations is resilient to enable this collaborative approach.
Because no organization operates alone, we must iteratively work with vendors, suppliers, and partners to co-develop resilient outcomes. Participants jointly identify cross-firm service dependencies, classify and prioritize affected services, and codify MVSLs and Service Delivery Objectives (SDOs) in plans, controls, and testing. Critical data sets are protected for confidentiality, integrity, and availability (CIA) (including effectively immutable storage and multiple-authorization deletion), recovery environments are provisioned and maintained, and independent evaluation and exercises verify that impaired-state operation can be established and sustained. Crucially, this includes coordinated, multi-party testing—tabletop, technical, and chaos-style exercises—so that dependencies, failovers, and communications are proven across the ecosystem, not just within a single enterprise.
Zero Trust provides the control language for making this real across organizational boundaries: assume breach, least privilege, and explicit verification so that collaboration does not expand the blast radius. Two guiding principles are especially relevant here: access is a deliberate act (all cross-organizational access, human or non-human, is intentional, time-bounded, policy-driven, and evidenced), and “inside out, not outside in” (protection starts from Operations-Critical services and critical data sets outward, rather than relying on a perimeter).
Disruptions increasingly originate or propagate through shared providers and integrations, making resilience an ecosystem property, not just an enterprise property. The ORF is designed so each participant follows common principles and rules—MVSLs, SDOs, protected critical data sets, tested recovery environments, and independent evaluation—that make the whole stronger and more resilient than the individual participants alone. Considering MVSLs across the ecosystem and conducting coordinated testing reduce the chance of systemic impact, make impaired-state operations predictable, and accelerate restoration for customers, partners, and counterparties when adverse events occur.
Finally, including important vendors and suppliers in the development and testing of resilient services is essential to the safety and soundness of our economy. It is not practical for each enterprise to test resilience one-to-one with every important supplier. These multi-sector exercises that span an ecosystem should be convened by an independent third party (e.g., BRC, ISACs, CSA) to ensure realism, neutrality, and broad participation.
Role of the Business Impact Analysis (BIA)
“Aligning the tone at the top with the resources in the ranks.”- Phil Venables
The Business Impact Analysis (BIA) is directly aligned with multiple Zero Trust guiding principles forming the basis of all resilience activities:
- Begin with the End in Mind (business/mission objectives)
- Inside Out, Not Outside In
- Breaches Happen
- Understand your Risk Appetite
- Ensure the Tone from the Top
The BIA also forms the basis for continuous improvement, supporting the Zero Trust guiding principle of “Continuously Monitor.”
The BIA assists the organization with the planning and implementation of Zero Trust principles. At its core, the relationship between resilience and Zero Trust is largely about Identity and Access Management (IAM) and managing the blast radius. The BIA is an accepted means of establishing priorities and determining dependencies by linking business strategy, security architecture, and operations. It begins with corporate policy and obligations, effectively establishing requirements and providing the basis for resilience testing to ensure objectives are met.
It is not unusual for larger organizations to develop a master BIA for the entire enterprise and then to have separate BIAs for key processes and parts of the organization. The latter is often referred to as an Activity BIA. This is done to handle complexity and to make the results more actionable. Some organizations have chosen to keep the resilience aspects as a separate document or an appendix to augment the BIA. For the purpose of this paper, we treat it as a single document.
Useful resources for learning more about developing BIAs include:
- The International Standards Organization (ISO)) has the most mature BIA references of the global standards. ISO 22317 (BIA) builds upon ISO 22300 (Security and Resilience) and ISO 22301 (Business Continuity Management)
- NIST SP 800-34 defines a BIA as, “Process of analyzing operational functions and the effect that a disruption might have on them”
- NIST IR 8286D, entitled “Using Business Impact Analysis to Inform Risk Prioritization and Response,” provides instructions on the development and use of a BIA
- The Business Resilience Council (BRC) under the Global Resilience Federation (GRF) has useful resources, as well
Through the lens of resilience and Zero Trust, the BIA is re-envisioned in key ways:
- Heavily influenced by external events (e.g., loss of a Cloud Service Provider (CSP))
- Addresses impact on the external ecosystem by internal events (e.g., ransomware)
- Driven by business priorities, business value of assets, and external obligations
- Heavy focus on dependencies between components that cooperate to deliver a business process, products, and services
- Addresses all three aspects of the confidentiality, integrity, availability (CIA) triad for each element
- Regards “acceptable” as a reduced level for a period of time until fully restored
It is important to remember when looking at impact that it is about business value, not technical severity. Using the BIA to establish priorities and to determine dependencies enables us to effectively allocate resources (e.g., capital, people, time, energy) to internal controls, including Incident Response (IR) and the protect, detect, and recover functions. These allocations can be made for global hazards without having to know every possible source of the hazard.
The BIA empowers us to align the business, security architecture, and operations.
Acceptable Levels
In the traditional worlds of Business Continuity (BC) and Disaster Recovery (DR), we rely primarily on two metrics: Recovery Point Objective (RPO) and Recovery Time Objective (RTO). RPO is the maximum allowable loss of data. RTO is the maximum acceptable downtime before it causes unacceptable business harm. Both are a measure of tolerance and drive practices throughout the enterprise (e.g., backup schedules).
In resilience, as opposed to BC/DR, we presume incidents and we recognize the advantages of operating in an impaired state while moving towards full restoration.
For each line item in the BIA, define the following:
-
Service Delivery Objectives (SDO): Defined by the ORF as, “The objectives that set the impaired level and time constraints for delivery of services in the event of a disruption”
-
Maximum Tolerable Loss: The maximum tolerable loss is typically measured in data (value, sensitivity, volume), value loss (e.g., revenue), or length of disruption
-
Minimum Viable Service Level (MVSL): Defined by the ORF as the lowest possible level of service delivery to enable customers, partners, and counterparties to deliver their critical services to their downstream customers, partners, and counterparties. The PCAST adopted the MVSL as defined by the ORF
-
The term is related to Impact Tolerance, defined by the Bank of England in Supervisory Statement SS1/21 as, “The maximum tolerable level of disruption to an important business service as measured by a length of time in addition to any other relevant metrics.” The MVSL is intended to meet the level of Impact Tolerance of customers, business partners, and counterparties. If there is a greater impact, or the service cannot meet the identified MVSL, then consumer harm and systemic impacts may occur
-
For example, “No more than 50,000 people will be without x (e.g., water, food, electricity, communications) for more than 1 week.” Example courtesy of Report to the President Strategy for Cyber-Physical Resilience: Fortifying Our Critical Infrastructure for a Digital World (page 27)
-
Organizations typically find it useful to set acceptable levels in the following order, with the integrity leg of the CIA triad gaining in priority with the increased adoption of Artificial Intelligence (AI):
- Availability (service delivery)
- Confidentiality (data loss)
- Integrity (data corruption)
These metrics are explored further in the Metrics and Indicators section.
Once Priorities Are Determined
After we have a stack ranking by management of what is meant to remain viable, we need to understand the relationships and dependencies by identifying the technology, the people, the process, and organizational dimensions that support each activity. Without knowing the underlying components, we cannot recover.
This directly maps to Zero Trust Step 1 of the five step process.
During this step, we also identify the sequence items that are restored. We cannot recover everything at once. Certain components are dependent on other items to be restored first.
The BIA helps establish an initial assessment of existing and desired levels of resilience.
Where to Find Obligations
While looking inside the four walls of the organization, we ask ourselves several questions, remembering the desired outcome is to stack rank technology, people, and processes by importance to the business.
- What is required to continue delivering our product and services?
- What is the minimal acceptable level we can deliver products and services to remain viable?
- What are the minimum viable levels for non-customer facing operations (e.g., payroll) to remain viable?
- How long can we go without each of these functions to remain viable?
Understanding single points of failure (SPOFs) is important. For each third party, ask yourself, “Can we operate without them?” and “How do we replace their role in the event of an incident?”
Be sure to look for where you are aggregating risk. This is a challenging task. By definition, a SPOF is a form of risk aggregation. Outside of SPOFs, we are looking for third parties that have large amounts of our data; are integrated in multiple business units, products, and services; or are engaged across our supply chain and industry. Why? As we continue to increase the business value held by a vendor, they become a larger target for malicious actors. As third parties grow in importance or the more connections they have, the greater the value to a malicious actor, thereby justifying greater commitment by the malicious actor and a greater risk to your organization.
Third Party Risk Management (TPRM)
In essence, we are looking at different forms of counter party risk and risk treatments. In today’s highly interconnected world, we cannot restrict our view to within our own four walls. The modern enterprise is highly dependent on external third parties including Cloud Service Providers (CSPs), Managed Service Providers (MSPs), and Managed Security Service Providers (MSSPs), all commonly referred to as External Service Providers (ESPs). Disrupting an ESP disrupts everyone with which they are connected.
The modern enterprise is almost always reliant on some form of supply chain. These can be highly complex, global supply chains like we see in industrial sectors like manufacturing, pharmaceutical, and aerospace. There are also simpler situations where back-office operations like payroll are outsourced and vendors are relied on for day-to-day maintenance, repair, and operations (MRO) ranging from office supplies to equipment. It is hard to find an organization that is not reliant on a software supply chain or a hardware supply chain.
The global nature of the business requires us to face the fact that an event on the other side of the world can ripple through, eventually impacting us. This is often referred to as contagion.
Interested Parties
Interested parties are the people and organizations to whom we are obligated. Interested parties fall into three categories:
- Our business’s internal obligations
- Upstream partners and customers to whom we supply products and services
- Downstream ESPs, partners suppliers, and vendors that we rely on
Obligations
The obligations help us understand minimal requirements to remain viable. Obligations come from several sources:
- Legislation
- Regulation
- Customers (including any communities served)
- Partners
- Corporate policies
- Operational needs
Our operational needs are often the easiest to forget. These are the operational items that are required to operate at acceptable levels. They often cut across large swatches of the organization. For example, identity and access control. If you restore an application or a business process but nobody can access the required application, you remain offline. If you do not have state information, you are not viable.
Each leg of the CIA triad is to be looked at separately. The confidentiality requirements are different from the availability requirements. Historically, the integrity leg is most important for devices, fraud, and effective operations. With AI, the integrity leg is growing in importance.
Introducing Abuse Use Cases to the BIA to Assess Adversarial Value
Traditionally, organizations prioritize cybersecurity investment on assets of most value to the organization. This approach conflicts with the typical attacker viewpoint, which is often focused on gaining access, sustaining that access, selling the access, or seeking out opportunities for extortion, theft, or fraud. By considering asset criticality both from the value to the organization and the value to an attacker, organizations can better prioritize investment to ultimately reduce the magnitude of impact from successful cyberattacks.
High Value Targets (HVTs) are information systems, data, roles, and processes for which unauthorized access, use, disclosure, disruption, modification, or destruction could cause a significant impact to an organization’s ability to perform its mission or conduct business. These systems may contain sensitive controls, configurations, instructions, or data that is then leveraged for critical information systems’ management. They may house unique collections of secrets, as well as be systems that perform defensive operations (such as delivering protect, detect, investigate, and respond capabilities). This methodology may be an extension of the “recognizability” factor described as the likelihood that potential adversaries would recognize that an asset is critical. HVTs can as well be referred to as transversal technology supporting important business services (or an organization’s crown jewels), which need to be identified and properly secured to better handle the environmental changes caused by an advanced adversary.
High Value Target Methodology
NIST Interagency Report (IR) 8286D reinforces this view by highlighting the importance of incorporating abuse case identification into risk assessments. Beyond traditional BIAs that often focus primarily on loss of availability, IR 8286D explicitly calls for also analyzing confidentiality and integrity abuse scenarios—understanding how attackers might exploit or manipulate data and systems—to ensure that adversarial value is fully captured in criticality assessments.
The Criticality, Accessibility, Recoverability, Vulnerability, Effect, and Recognizability (CARVER) target analysis and vulnerability assessment methodology is a way of completing the analysis.
Metrics and Indicators
“You can’t control what you can’t measure.” - Tom DeMarco
Metrics are objective measurements. Indicators are used to attract your attention for further investigation. Often it is not the metric that is important. Rather, it is the trend over time that is the most useful.
Think of your car’s dashboard. The check engine light is the indicator. Your mechanic running diagnostics provides the metrics to be used to uncover the root cause and remediate.
Indicators come in three types:
- Leading Indicators: These are the hardest to define and the most valuable. Leading indicators tell you something is likely to happen. The best leading indicators provide a sense of when and the impact
- Coincident Indicators: These tell you something is happening
- Lagging Indicators: These tell you something happened
The resilience community originally defined a new metric called the Maximum Tolerable Period of Disruption (MTPD) as the maximum time a business can experience a disruption before it faces unacceptable consequences like financial loss, reputational damage, or regulatory non-compliance. MTPD is effectively a version of RPO and RTO focused on a particular business process or function.
MTPD is also known as Maximum Acceptable Outage (MAO) or Maximum Tolerable Downtime (MTD). In practice, the Minimum Viable Service Level (MVSL) we used to develop the BIA is the most useful because it can be associated with individual business processes, products, and services.
The President’s Council of Advisors on Science and Technology (PCAST) report, “Strategy for Cyber-Physical Resilience Fortifying our Critical Infrastructure for a Digital World,” made the following recommendation to the U.S. President. Subsequently, this recommendation and three others were adopted and included in the U.S. National Strategies while under consideration by other countries and bodies. The recommendations are aligned with the principles contained in the ORF, and the ORF is one of the inputs to the report.
-
Recommendation 1: Establish Performance Goals. Set minimum delivery objectives for critical services, even in the face of adversity, and establish more ambitious performance goals to measure all organizations ability to achieve and sustain those objectives
- Recommendation 1A: Define Sector Minimum Viable Operating Capabilities and Minimum Viable Delivery Objectives
- Recommendation 1B: Establish and Measure Leading Indicators
- Recommendation 1C: Commit to Radical Transparency and Stress Testing. Executive Metrics are objective, measurable values used to assess progress towards reaching goals. Metrics help identify waste and inefficiencies, set realistic goals, compare performance to desired outcomes, and provide data to determine if adjustments are needed to achieve the desired outcomes
Example Minimum Viable Operating Objectives and Minimum Viable Delivery Objectives
-
Bounded Impact: Expresses the minimum delivery goals and is directly aligned with the Zero Trust principle of limiting the blast radius. For example, no more than 50,000 people will be without x (e.g., water, food, electricity, communications) for more than 1 week
-
Bounded Failure: A measure of the maximal impact of any single failure via containment of spread by creating independence and resilience of subsystems and components to failures of other components. Bounded Failure is also directly aligned with the underlying principle of limiting the blast radius emphasizing the drive to eliminate (or minimize) single points of failure (SPOF) and avoid the risk of cascading failures (cascading risk). You can see how segmentation and micro-segmentation can be used to prevent (or limit) an event causing additional events across the enterprise or outside of the enterprise
Having business partners who practice Bounded Impact and Bounded Failure help ensure events experienced by them avoid or at least limit damage to others in the ecosystem, avoiding contagion.
Leading Indicators
The intent of these metrics is to identify an organization’s most critical systems. Specific metrics would be created in the context of each sector and organization.
PCAST lists the following:
- Hard Restart Recovery Time
- Cyber-Physical Modularity
- Internet Denial/Communications Failure
- Fail-Over to Manual Operations
- Control Pressure Index
- Software Reproducibility
- Preventive Maintenance Vibrancy
- Inventory Completeness
- Stress Testing Vibrancy (red teaming)
- Common Mode Failures and Dependencies
Useful Metrics to Track
Organizations find it useful to track Single Points of Failure (SPOF), where risk is being aggregated, and sources of cascading risk (aka, cascading failure). These are useful to track while executing your program and during day-to-day operations. While remediating, it is recommended to track metrics like percentage of SPOFs remediated, variance of aggregated risk to risk tolerance, and percentage of cascading risk mitigated.
During day-to-day operations, it is useful to instrument, monitor, and track unremediated SPOFs. It is not unusual to have known risks, tracked in your risk register, that are not remediated for one reason or another (e.g., accepted, not feasible).
Additional useful metrics for consideration:
- Board: What threshold of what metric if exceeded (or not adhered to) demands immediate escalation to the Board? What is the most extreme but plausible scenario that we feel like we cannot withstand? What percentage of your infrastructure (on-premise or cloud) is software defined, follows an immutable infrastructure pattern and for which the configuration code is reproducible?
- Time to Reboot the Company: Imagine everything you have is wiped by a destructive attack or other cause. All you have is bare metal in your own data centers or empty cloud instances and a bunch of immutable back-ups (tape, optical, or other immutable storage). Then ask, how long does it take to rehydrate/rebuild your environment? In other words, how long does it take to reboot the company?
- Blast Radius Index: What percentage of roles in your organizations have a potential incident (insider risk or error driven) damage blast radius greater than the organization span of the role N steps (e.g., N=2) above that in the organization? For specific lines of attack (e.g., application compromise, e-mail delivered malware, web drive-by-downloads), what is the average level in the defense-in-depth stack that stops the attack and at what point is the attack detected?
- Reproducibility: What percentage of your entire software is reproducible through a CI/CD pipeline? If this percentage is low, then inevitably the time to resolve vulnerabilities or completeness of resolution will not be what you want
- OODA Spread: How much faster (or slower) is your OODA loop than your attacker’s? Responsiveness and adaptiveness in the face of an attacker’s capabilities and intent is a key signal of how likely you are to be subject to a successful attack
As well, the Cyber Resilience Index metrics measure an organization’s ability to anticipate, resist, adapt, and recover from cyber threats by assessing both preventive controls (governance, detection, protection) and response/recovery capabilities.
Technical Debt and Operational Technology (OT) Equipment Not Built for a Digital World
The measure of technical debt and OT equipment not built for a digital world is a leading indicator.
Technical debt is a term of art referring to the long-term costs of using suboptimal or outdated systems, like old servers, software dependencies, or poor security practices, instead of more robust, modern solutions. It can also refer to overly complex situations. Whatever form it takes in your enterprise, technical debt causes complexity, increases costs and consumes resources, creating risk to your enterprise. Organizations with a high level of technical debt often suffer from an inability to successfully implement both Zero Trust and resilience. A high level of technical support is often required to keep these suboptimal systems running, taking away resources from technical improvement.
OT equipment, like ICS, was often built to control physical processes not to manage digital information like IT. OT systems were initially designed to be isolated, reliable, and focused on physical operations, with security and connectivity as afterthoughts. While the core principles apply to OT, the tools and techniques are implemented quite differently. These fundamental differences create challenges as organizations demand IT/OT convergence. Incidents like Colonial Pipeline have highlighted how cyber incidents in IT systems can quickly impact the physical world.
Technical debt and OT equipment not built for a digital world can be the result of many things like independent growth, rapid growth, and merger and acquisition (M\&A) transactions. Whatever the cause, the result is increased likelihood of an incident, greater impact, slower detection, and prolonged resolution.
The tracking and measurement of technical debt and OT not built for a digital world are a leading indicator. While a universal measurement does not exist, some tools do exist. The standard for understanding IT software defined by the Consortium for Information & Software Quality (CISQ) is an example.
Role of the Supply Chain
The supply chain touches upon several Zero Trust guiding principles:
- Access is a Deliberate Act
- Breaches Happen
- Understand Your Risk Appetite
- Ensure the Tone from the Top
- Instill a Zero Trust Culture
- Continuously Monitor
The BIA addresses the significance of different members of the supply chain, recovery priorities, and the order of recovery.
The Age of Interconnection
In today’s global, digital business landscape, our organizations do not exist in isolation; they are nodes within sprawling, interconnected networks of suppliers, customers, logistics, technology providers, and regulatory bodies. An ecosystem that arguably guarantees both mutual destruction and mutual benefit! Events and disruptions in distant organizations can rapidly cascade through networks, upending operations, finances, and reputations.
- In 2025, fewer than 8% of organizations feel they have full control over their supply chain risks, while 63% report supply chain losses are above expectations
- Supply chain disruptions increased by 30% in the first half of 2024 compared to the previous year
- The interconnectedness means risk contagion; what happens to a single node, entity or partner can quickly propagate, affecting upstream and downstream suppliers, customers, and the broader ecosystem
How Other Organizations Impact Us and Vice Versa
-
Outbound Risk Amplification: If a critical supplier fails, outages, missed deliveries, or data breaches can quickly impact our ability to serve customers. Likewise, disruptions in our organization, cyber breaches, financial distress, compliance violations—not only affect us, but also propagate upstream to our partners and customers
-
Counterparty Risk and Contagion: Counterparty risk refers to the possibility that the entities we rely on (e.g., suppliers, vendors, customers) may themselves default, introduce systemic risk, or experience shocks that spread through the network. The concept of contagion in supply chains means incidents are not contained; a disruption, cyberattack, or compliance failure at one point can quickly travel across partners, even to entities with robust internal controls
Regulatory and Legislative Pressures
In recent years, we have seen a steady shift in global legislative and regulatory focus on supply chain risk. The EU’s Digital Operational Resilience Act (DORA), NIS2, and UK’s PRA requirements enforce strict third-party management and supply chain security standards for financial firms and critical infrastructure.
What is UK PRA?
The Prudential Regulation Authority (PRA) is a detailed framework for UK financial firms promoting safety and responsible risk management across the banking and insurance sectors. This ensures that third-party vendors and suppliers working with PRA-regulated firms, especially in the technology and cyber domain, face more direct regulatory scrutiny and a need for demonstrable security resilience and transparency.
Impact on Third-Party Vendors/Suppliers
From January 2025, the new Critical Third Parties (CTP) Regime gives UK regulators direct oversight of suppliers whose services are considered systemically important to the financial sector. Designated CTPs must comply with stricter requirements covering risk assessment, resilience measures, and supply chain oversight.
All significant third-party arrangements, including those not technically “outsourcing,” are subject to robust risk management expectations, including cybersecurity controls, business continuity, and incident response plans. Material non-outsourcing vendors face requirements similar to critical outsourcers, proportional to the risk level.
Financial firms must ensure that third-party contracts include clear security and compliance clauses, audit and access rights, and notification duties for any incidents affecting services.
All information and communication technology (ICT) suppliers must meet UK and global standards for cybersecurity (e.g., Cyber Essentials Plus), GDPR/data protection, and ongoing operational resilience.
Firms are required to notify the PRA about material issues with vendors, such as if a supplier can’t meet security contract terms or if the arrangement poses unique risks.
The overall aim is to reduce systemic risk from supplier failures, particularly due to cyberattacks or technology disruptions, and to ensure that both firms and regulators can monitor and intervene in supplier relationships as needed.
Seventy-five percent of supply chain leaders in 2025 noted board-level engagement and regulatory compliance as top priorities, citing a dramatic increase from previous years. Standards such as ISO 28000 (Supply Chain Security Management system (SCSMS)) and the NIST Cybersecurity Framework now explicitly define supply chain risk management as core requirements.
Legislation is now driving organizations to:
- Map out their supply chains, including subcontractors, fourth parties, and software dependencies
- Monitor for single points of failure (SPOFs) and aggregate risk exposure
- Conduct regular supplier audits, scenario testing, and resilience planning
- Demonstrate proactive risk management and incident reporting
Statistics and Metrics: The Risky Reality
According to a recent survey of 546 IT directors and CISOs by cybersecurity ratings vendor SecurityScorecard
- Seventy-one percent of organizations experienced at least one material third-party cybersecurity incident in the past year, and 5% reported ten or more such incidents,
- Supply chain attacks surged by 431% between 2021 and 2023, with projections for further dramatic increases
- Forty-five percent of organizations globally are expected to experience attacks on software supply chains by 2025—a threefold increase from 2021 levels
- The average cost of a cyber-related supply chain data breach reached $4.88 million in 2024, a 10% increase year over year
- The percentage of businesses that cite cybersecurity as their primary concern in ensuring supply chain resilience is 55.6%
- Sixty-two percent of leaders expect labor shortages to present ongoing short-term supply chain risk
- Nearly one-third of organizations now prioritize dual-sourcing and supplier diversification to mitigate disruption.
Other Important Metrics.
- Eight percent of organizations have full supply chain risk control
- Sixty-three percent report higher-than-expected losses
- Supply chain disruptions rose 30% in the first half of 2024
- Supply chain attacks are up 431% from 2021-2023
- $4.88 million average cost of supply chain cyber breach (2024)
- Cyber risk is the top supply chain concern for 55.6% of businesses
- Closer collaboration is the number one improvement strategy for 54% of leaders
Single Points of Failure (SPOF) and Risk Aggregation
A single weak link, whether it’s a supplier, logistics provider, or technology vendor, can act as a SPOF, threatening the entire value chain.
-
Digital transformation has intensified SPOF risks. A vulnerable API or software dependency can put multiple organizations at risk simultaneously
-
Aggregating risk occurs when too many dependencies, risks, or critical services are concentrated with one or a limited number of suppliers, regions, people, or technology, magnifying impact if a disruption occurs
-
In certain industries, customer failure can lead to a whole supply chain failing. Manufacturing industries, such as the motor trade, are an example of this. Many component factories are set up to supply large vehicle manufacturing plants. If the vehicle manufacturer has to stop production, the impacts cascade to the entire supply chain, many of which may be less resilient than the manufacturer themselves
Testing the Chain: Scenario Simulations and BIA Scenario Testing and Simulated Failure
- Effective supply chain risk management requires regular scenario testing that simulates supplier outages, cyberattacks, financial distress, and regulatory incidents
- Scenarios are designed to exercise items identified in the BIA
- These exercises reveal vulnerabilities, help calibrate response plans, and identify operational dependencies before real-world incidents occur
Business Impact Analysis (BIA)
- The BIA establishes priorities and criteria by mapping critical processes, dependencies, and recovery timelines
- BIA drives resource allocation, incident response planning, and investment in resilience by focusing efforts on the most business-critical areas
Strategic Implications: Building Resilient Supply Chains and Collaborative Risk Management
- Fifty-four percent of organizations now improve supply chain risk management through closer collaboration with suppliers and customers
- Mapping and sharing information on risk hot-spots, aggregated exposures, and SPOF locations is increasingly standard practice
Proactive, Technology-Enabled Approach
- Investments in supply chain mapping, scenario testing, real-time analytics, and cross-functional risk oversight are rapidly increasing
- Only organizations that integrate risk management across procurement, compliance, IT, and business units will be ready for unpredictable shocks
We live in an era of radical interconnection. Supply chain risks are now shaped by contagion, counterparty exposures, and SPOFs, which all threaten financial, operational, and reputational stability. Regulations, standards, and legislative mandates have elevated supply chain risk management to an executive- and board-level priority where it gets the support, visibility, and monitoring it deserves to drive culture change and operational impact.
To thrive, organizations must:
- Recognize and map their interconnected risk landscape
- Embed scenario testing and BIA-driven priorities
- Address counterparty and aggregated risks proactively
- Build collaborative relationships and technology-enabled supply chain oversight
The organizations best prepared for tomorrow’s supply chain risks will be those that embrace resilience, agility, and cross-boundary accountability today.
Aligning Zero Trust in the Supply Chain Ecosystem
Implementing Zero Trust principles within the third-party supply chain ecosystem significantly strengthens cybersecurity by eliminating implicit trust and enforcing continuous verification of every access request. This approach ensures that vendors and suppliers only receive the minimum required access, limiting breach impact and preventing lateral movement of threats. By incorporating strict access controls, multi-factor authentication, and micro-segmentation, Zero Trust minimizes vulnerabilities across complex, interconnected supply chains.
Moreover, Zero Trust supports ongoing regulatory compliance by providing transparent audit trails, enforcing consistent security policies across all supply chain participants, and simplifying adherence to standards such as GDPR and sector-specific regulations. This fosters accountability and timely incident reporting, thereby reducing regulatory risks.
For stakeholders, Zero Trust delivers measurable assurance through continuous monitoring, risk assessments, and ongoing validation of third-party security postures. This proactive resilience approach sustains a strong and adaptive security posture, enabling trust and confidence in supply chain integrity and operational continuity.
The below metrics are used to effectively report Zero Trust ROI to the board:
- Reduction in Risk Exposure (%): Measures how much Zero Trust implementation has lowered the organization’s cyber risk profile. For example, reduction in identified vulnerabilities or attack surface exposure
- Mean Time to Detect (MTTD) and Mean Time to Respond (MTTR) Improvement: Track the decrease in the time taken to detect and respond to security incidents, demonstrating enhanced operational resilience and incident control due to Zero Trust controls
- Cost Savings and Avoided Incident Losses ($): Quantify the financial return by calculating savings from reduced breach incidents, streamlined security operations, and compliance penalties avoided through improved security posture
ISO 28000 and the Supply Chain Ecosystem of the Future
ISO 28000 is set to impact the future of supply chain security, resilience, and compliance by providing a comprehensive framework for managing security risks across all activities and levels of the supply chain. The standard emphasizes a structured, proactive approach to identify, assess, and mitigate security-related risks, including dependencies and interdependencies within the supply chain.
By requiring organizations to align security management processes with their business objectives, ISO 28000 promotes integrated enterprise resilience and systematic management practices. It mandates continuous monitoring, evaluation, and improvement of security controls, enabling organizations to respond dynamically to evolving threats and vulnerabilities.
Additionally, ISO 28000 supports compliance with statutory, regulatory, and voluntary obligations, increasing credibility and trust among stakeholders. Its harmony with other management standards like ISO 9001 and ISO 22301 streamlines governance. This makes it easier for organizations to embed security management into operational and risk management frameworks. Overall, ISO 28000 advances supply chain security by fostering resilience, transparency, and accountability, ensuring organizations can sustain secure and compliant supply chains in an increasingly complex global environment.
ISO 28000 aligns with Zero Trust security principles by sharing core concepts focused on risk management, continuous verification, and minimizing trust assumptions across the supply chain ecosystem. Both frameworks emphasize a proactive, structured approach to security that requires ongoing assessment and control of access to critical assets.
ISO 28000’s focus on security and resilience management supports the Zero Trust tenet of “never trust, always verify” by demanding rigorous risk assessments and continuous monitoring of supply chain activities. It also advocates for strict control over who and what can access assets, paralleling Zero Trust’s least privilege access principle that limits exposure and reduces potential attack surfaces.
Furthermore, ISO 28000’s integration with organizational processes and regulatory compliance mechanisms complements Zero Trust’s dynamic authorization and real-time policy enforcement. Together, they build a resilient supply chain security posture where trust is explicitly validated, threats are contained quickly, and visibility across third-party relationships is improved, ensuring compliance and operational continuity in uncertain threat landscapes.
Software Supply Chain Security
The Zero Trust guiding principle of “never trust, always verify” extends to the software supply chain, a domain where building resilience is paramount for the modern enterprise. In today’s interconnected digital landscape, software is rarely built from scratch; it is instead assembled from a global ecosystem of open-source components, third-party libraries, and automated toolchains. This complex network of code, tools, processes, and people constitutes the modern software supply chain. Over the years, we have seen incidents like SolarWinds, Log4j, and MOVEit avoid typical defenses, causing widespread disruption. We can imagine how a malicious actor will use these techniques to disable essential services at a time of their choosing.
The threat landscape continues to evolve with alarming sophistication. In 2024, researchers discovered over 100 malicious Artificial Intelligence (AI) and Machine Learning (ML) models on the popular Hugging Face platform. Some of these models were engineered with a silent backdoor, designed to execute malicious code upon being loaded by an unsuspecting data scientist or developer. This incident highlights a new and potent attack vector, proving that even the foundational components of AI development are now part of the supply chain that must be secured to ensure enterprise resilience.
As developers turn to AI more often to assist with code generation a new potential attack vector is opened. Indirect AI prompt injection (or poisoning) is a method of degrading or poisoning the data in an LLM. If an attacker does this, under certain conditions it could give developers code with hidden backdoors or unexpected actions.
The September 2025 Shai-Hulud incident was a large-scale, self-propagating worm that infected over 500 packages in the npm JavaScript registry, making it a significant software supply chain compromise. It is considered one of the largest npm attacks in history.
The OWASP Top 10 for 2025 lists software supply chain failures in the top three risks behind access control and misconfigurations.
Applying Zero Trust Principles for a Resilient SDLC
Access to any part of the Software Development Lifecycle (SDLC) must be treated as a deliberate act that requires explicit verification at the following levels:
-
Source Code: Do not implicitly trust code commits, even from known developer accounts. An attacker can compromise developer credentials to inject malicious code. Resilience begins with source integrity:
- Mandate that all code commits are cryptographically signed to provide a verifiable, non-repudiable record of authorship
- Enforce branch protection rules that require peer reviews for all changes to critical branches and paths
- Implement strong, role-based access controls (RBAC) with multi-factor authentication (MFA) and the principle of least privilege for accessing all source code repositories
-
Dependency: Do not implicitly trust any third-party or open-source software components. Modern applications are composed of up to 90% open-source code, making dependencies the largest attack surface. Attackers exploit this trust with techniques like typosquatting and dependency confusion, where a malicious public package impersonates a legitimate internal one:
- Establish a private artifact repository to act as a secure, curated source for all dependencies, proxying public sources and enforcing policies that block malicious or vulnerable packages
- Configure and perform frequent dependency scanning audits, and introduce these processes into the earliest stages of the SDLC
- Use dependency pinning mechanisms to pin every dependency to a specific, vetted version, preventing unexpected and potentially malicious updates that could compromise resilience
-
Build Process: Do not implicitly trust the build pipeline or the artifacts it produces. The Continuous Integration/Continuous Delivery (CI/CD) pipeline is a high-value target; compromising it allows an attacker to poison all software produced by the organization:
- Execute all builds in ephemeral, isolated environments that are destroyed after each run to prevent tampering or cross-contamination
- Every build artifact must be digitally signed to ensure its integrity
- Ensure that CI/CD automation workflows always authenticate on behalf of the user, and operate under the principle of least privilege
- To provide verifiable proof of a secure build, generate provenance. Provenance is often represented as a cryptographically signed attestation of how, when, and from what source an artifact was built. This creates a reproducible build, a strong countermeasure that allows independent verification that a binary matches its source code
-
Deployment: Do not implicitly trust an artifact just because it resides in a trusted repository. Configure deployment systems as Zero Trust policy enforcement points. Before any artifact is deployed, these systems must automatically verify its digital signature and provenance attestation. This final check ensures that only authentic, untampered software built by a trusted process can run in your environment, a critical control for operational resilience
Assume Breach: The Core of Supply Chain Resilience
A core tenet of Zero Trust is to assume that a breach is inevitable. The 2021 Log4j vulnerability (CVE-2021-44228), where a flaw in a single, ubiquitous logging library created a catastrophic vulnerability across the internet, perfectly illustrates this principle. Many organizations were vulnerable without even knowing they used the component, as it was often included as an indirect, or transitive, dependency.
Achieve Visibility with a Software Bill of Materials (SBOM)
Resilience depends on the ability to rapidly detect, contain, and recover from a compromise. When it comes to the software supply chain, the foundational tool for this is the SBOM. An SBOM is a detailed, machine-readable inventory of every component—open-source libraries, third-party binaries, proprietary modules, and their respective versions—contained within a software product. It is a formal, nested inventory of every component within your software and provides a foundational piece of the security by design.
As defined by the U.S. National Telecommunications and Information Administration (NTIA), an SBOM provides the transparency needed to manage risk. When a new vulnerability is disclosed, organizations with a comprehensive set of SBOMs can immediately determine every application affected by the flaw.
The following are the key attributes of an SBOM that make software resilient in a Zero Trust environment:
-
Visibility and Inventory: Knowing what is inside the software eliminates any blind spots. This will also enable the immediate identification of any vulnerable components and facilitate an impact assessment
-
Patch Management: SBOMs map affected components to CVE alerts, triggering patching. The entire process can be automated and executed without human intervention, before hackers can exploit
-
Incident Response: If an incident occurs, the SBOM instantly reveals which component may have been compromised, thereby narrowing the forensic scope, reducing root cause analysis time, and increasing response time
-
Compliance and Auditing: An SBOM helps present evidence of due diligence quickly, simplifying audits and reducing the risk of penalties
-
Risk Management: An SBOM tremendously reduces the time to manage third-party risk in the software supply chain
A Zero Trust policy engine can leverage these SBOM attributes to continuously monitor the risk associated with any software components by reducing the attack surface and enhancing software resiliency.
The value of an SBOM is highlighted by events reported with Log4j. Years after the issue was reported, organizations and software vendors continue to report issues because they cannot identify where Log4j exists, while vendors making use of SBOMs were able to properly identify and advise enterprises within hours.
Implement a Resilient Incident Response Protocol
An effective response requires a structured plan. The NIST Computer Security Incident Handling Guide (SP 800-61) provides a proven, four-phase lifecycle for building resilience:
-
Preparation: This phase involves establishing an incident response plan and the necessary tools. For supply chain resilience, this critically includes the proactive generation and maintenance of SBOMs for all software assets
-
Detection and Analysis: Upon the disclosure of a new threat, the SBOM inventory is used to rapidly assess the scope of the disruption and determine which applications, systems, and environments are affected
-
Containment, Eradication, and Recovery: The goal is to limit the damage and restore normal operations. This involves isolating affected systems, blocking the malicious component, and deploying a patched or clean version of the software. The key metric for resilience here is Mean-Time-to-Recover (MTTR), defined as the period it takes to return to normal operations following a disruption
-
Post-Incident Activity: A “lessons learned” phase is conducted to understand the root cause and improve defenses, strengthening the organization’s resilience against future incidents. This is also a good opportunity to update the plan itself based on what went well and what could have been improved. Training opportunities are also often identified in post-incident activity
Adopting Frameworks for Resilient Governance
Implementing a Zero Trust approach to securing the software supply chain should not be an ad-hoc effort. Practitioners can rely on established, authoritative frameworks to provide a structured and measurable path to maturity:
-
NIST Secure Software Development Framework (SSDF) (SP 800-218): Use the NIST SSDF as a comprehensive guide for establishing organizational governance and defining high-level security practices across the SDLC. The SSDF provides a common vocabulary and set of outcome-based practices for producers and acquirers of software, helping organizations reduce vulnerabilities and improve resilience
-
Supply-Chain Levels for Software Artifacts (SLSA): The SLSA framework provides the specific, technical steps for preventing tampering and ensuring artifact integrity. It offers an incremental, four-level maturity model for producing verifiably secure software artifacts, allowing organizations to start small and focus on quick wins while building toward a hardened, resilient posture
Operational Technology (OT) Resilience
Resilience in Operational Technology (OT) is the ability to remain viable amidst adversity. Process control networks that make up the cyber-physical components of OT operations, must prioritize availability due to the nature of the products, services, and resources they provide.
Disruptions to industrial control systems (ICS), devices, process control networks, and centralized monitoring and control of these systems can result in widespread disruption to critical entities and sectors. Given that OT systems often control physical processes like the electric grid, critical food and pharmaceutical manufacturing, the purification and delivery of clean water, and more, a lack of resilience can lead to safety issues and widespread service failures. Resilience demands a comprehensive approach that includes device visibility, cybersecurity measures, incident response planning, and training to ensure continuous operation, containment ,and eradication of threats.
Special Considerations
OT often includes legacy controllers and field devices with proprietary and insecure protocols. These are most often programmable logic controllers, distributed control systems, human-machine interfaces, and some supervisory control and data acquisition (SCADA) systems. However, there are more modern versions of these systems as well. Proprietary protocols are fieldbus and ethernet communications protocols that facilitate communication between wired devices and controllers in industrial settings.
There are sometimes open and interoperable protocols based on industry standards, and others individually developed by original equipment manufacturers (OEMs) for deterministic communications. They are versatile by design to ensure predictable and reliable data exchange with minimal latency for simultaneous and asynchronous real-time communications. They have limited functionality and memory, are unsigned and unencrypted, and are not used to add or enforce security measures. Some operational systems running proprietary protocols are considered end of life and no longer supported by their OEMs.
In brownfield deployments, legacy infrastructure is often layered with modern OT systems like building management systems, energy management systems, internet-of-things (IoT) devices, automation and robotics. These leverage different protocols that support higher bandwidth, ultra-low latency, and support huge fleets of devices. These systems, networks, and environments require nuance when considering security risks, vulnerabilities, mitigations and compensating controls.
From tanks and turbines to escalators and thermostats, the primary concerns for these systems are human and environmental safety, availability, and reliability of systems and processes. The process is often the cornerstone of business for the delivery of products, services, or resources that rely on operational technology. That process often involves layers of coordinated autonomy. Sensors for pressure, speed, volume and flow, along with actuators like motors, valves, and robotic arms, execute programmable logic relayed to them by control systems, often recording real-time conditions in the process.
These real-time conditions, as well as the software applications running the control systems logic, are accessible at supervisory stations (often Windows computers or standalone tablets) where operators and technicians interface with distributed operational technology at a centralized location, or remotely, via software applications. Lastly, the real-time conditions in the process that are recorded by monitoring systems are typically captured for historical pattern analysis and enterprise resource planning for the business.
IT systems have vulnerabilities likely to be exploited in similar ways across mainstream and ubiquitous systems, allowing for streamlined tools to monitor and triage security priorities. Many tools in IT allow for automated remediation. However, these tools can cause disruption in more delicate and complex OT networks. IT systems can also be easily isolated or removed from networks to contain and remediate incidents, where OT systems need to remain connected and operational. IT systems are typically replaced in 3-5 years while OT systems may remain in process control networks for 15 or more years in some sectors.
Due to the vendor ecosystem and purpose-built functionality of OT, security is often proprietary, and requires case-by-case distinctions. IT cybersecurity practices, analytics, forensics, and detection tools do not match the unique data and connectivity requirements and various configurations of OT environments. For example, running IT scanning tools like Nmap to identify vulnerabilities in OT networks could send queries to OT systems that are incompatible and disrupt the systems or processes.
OT Ecosystem
The ecosystem of operational technology is complex, with different stakeholders across sectors. These companies have various means, methods, and points of view for how to secure OT depending on the sector they operate in.
- Asset Owner: Responsible for ownership, operations, maintenance, and emergency response for applicable OT systems and processes under their control
- Vendors: OEMs responsible for development of OT hardware and software, operational guidance, support, maintenance, and emergency response guidance for sold and distributed OT systems
- Integrators: Specialized entities or companies that focus on the design, implementation, and third-party maintenance of automation and control systems across various industries
- OT-Centric Solution Providers: Private sector tools for asset management, monitoring, intrusion detection and behavior analytics, cyber threat intelligence feeds, incident response, and third-party managed services dedicated to OT systems and networks
- Security Researchers: Dedicated OT researchers that reverse engineer hardware and software to report vulnerabilities to OEMs, federal agencies, private sector, and international information sharing platforms and mechanisms
OEMs have traditionally required some level of control over their deployed systems to coordinate maintenance and patching support for their equipment, as well as integrations for security solutions. Systems that are not fully managed or entrusted to owners and operators in different operational business models are outsourced to third parties (e.g., integrators, MSSPs) with checks and balances further delegated to laws, regulations, compliance, and insurance.
Despite increased awareness, pressure, and oversight from governments, boards, and insurance providers, the scale and complexity of the OT landscape remains high due to the following, as further elaborated in CSA Zero Trust Guidance for Critical Infrastructure guidance:
-
Nature of OT Systems and Functions: Similar, but not identical, industries, technologies and use cases
-
Process Oversight and Configurations: Inconsistent change management and documentation processes
-
Supply Chain Complexity: Reliance on third-party systems and components with unknown provenance and missing chain of custody
-
Threat Intelligence: Lack of centralized telemetry and analysis of external threat actors and tactics, techniques, and procedures (TTPs)
-
Competing Metrics: Several risk management, methodologies, assessments, and security best practices
-
Limited Security Controls: Having security policies that are difficult to apply to legacy technologies creates different structures for compensating controls and security policy enforcement depending on each environment
-
Sector vs. Geographic Legislation: There are significant competing compliance standards, regulations, and requirements for sectors, states, nation-states, and other designations based on legislation for reporting requirements for what is considered critical and what is considered a significant cyber incident
-
Legislative and Regulatory Scrutiny: Critical infrastructure sectors with mission-critical OT systems are routinely included in strong legislative and regulatory requirements, however, the specific enforcement mechanisms vary widely by sector and region. There is no systemic understanding of interconnected cyber-physical infrastructure and cascading risks to critical services that focus at the asset level. There are also various definitions, standards, and metrics for measuring compliance and risk management across critical infrastructure sectors
-
Traditional IT Practices Do Not Translate to OT: Many common practices in IT do not translate to OT. Quite often IT practices presume operating systems, processing on the device, ability to perform security functions and the like. Quite often OT systems and devices do not possess these qualities
-
Long Useful Lives: In IT, assets often have a useful life of three to five years. In OT, assets can have useful lives measured in decades
-
Legacy Infrastructure: OT often includes older, legacy equipment and industrial protocols not designed with security in mind or easily augmented with security controls
-
Downtime Consequences: Failures in OT environments can lead to significant financial losses, safety hazards, and a loss of public trust
Creating and Maintaining a Definitive View of Your OT Architecture
The Creating and Maintaining a Definitive View of Your Operational Technology (OT) Architecture guidance builds on recent government direction for building defensible architectures in OT sectors. It was written to help critical infrastructure organizations create and maintain a definitive view of operational technology architecture stacks, focusing on asset inventory and management. It details asset inventory best practices and manufacturer-provided data and resources for building out an inventory. It also suggests ways to conduct more comprehensive security risk assessments once an inventory is up-to-date and the process for prioritizing critical and exposed systems.
Like CSA Zero Trust Guidance for Critical Infrastructure guidance, it describes appropriate security capabilities for managing risks, including third-party risks, and aligning to specific standards like the ISA/IEC 62443 and ISO/IEC 27001. The ISA/IEC 62443 addresses security for operational technology in automation and control systems. It is a series of standards to define requirements and processes for implementing and maintaining electronically secure industrial automation and control systems (IACS). These standards set best practices for security and provide a way to assess the level of security. IEC 62443 establishes a holistic approach to bridging the gap between operations and information technology as well as between safety and security.
The ISA/IEC standards are well adopted across all sectors that use IACS, including building automation, power, energy, medical devices, transportation,oil, gas, and chemicals.
Cybersecurity Framework (CSF) 2.0, NIST SP 800‑53 Rev. 5, CSA Cloud Controls Matrix (CCM) v4.1, and Zero Trust Guidance for Critical Infrastructure provide valuable guidance for building resilient systems but do not specify mandatory testing requirements. This dual-tier landscape ensures that Zero Trust resilience testing programs can achieve regulatory compliance through specific mandates while leveraging broader framework guidance to enhance overall cyber defense, business continuity, and organizational resilience capabilities.
The subsequent Zero Trust Implementation Process for OT section provides practical, repeatable process guidance for OT and Critical Infrastructure environments.
The Use of Digital Twins to Measure and Improve Cyber Resilience
“All models are wrong, but some are useful” - E. P. Box
Digital twins are virtual models of systems, often connected to real-time data, that simulate the behavior of real systems. Digital twins allow us to simulate scenarios, assess the impact of changes, and perform certain types of testing without impacting real-world operational systems.
A digital twin enables modeling of various types of threats, disruptions, mitigations, and recovery without impacting operations or incurring the costs of system changes. High-fidelity digital twins model business functions, processes, the ecosystem, assets, data flows, software catalogs, and access controls, allowing us to explore impacts on the enterprise.
Digital twins enhance resilience by creating virtual models of physical systems, such as supply chains and factories, to simulate proposed protective measures, test for disruptions, and practice restoration procedures in a safe space without incurring implementation costs or operational impact. Digital twins almost always allow us to run simulations faster, more safely, and at lower cost than in the real world, enabling proactive risk assessment, optimized response planning, predictive maintenance, and faster recovery, shifting from being purely reactive to remaining viable amidst adversity. Digital twins offer real-time visibility and insights, helping organizations understand cause-and-effect, test changes, including reconfigurations, and implement mitigations without touching the real-world system.
Key uses of digital twins for resilience include:
- Strategic planning
- Threat assessments
- Risk assessment
- Impact assessment
- Controlling the blast radius
- Stress testing
- Design testing
- Dependency identification
- Risk cascading
- Identifying single points of failure
- Identifying risk aggregation
- Assessing counterparty risk
- Response, containment, and recovery
- Predictive maintenance
NASA has the SunRISE project with the Jet Propulsion Laboratory (JPL) using a digital twin to build security into a program from the beginning, rather than retrofitting at the end. In addition to improving security at a lower cost, they have found a use for the digital twin to accelerate the assessment process and obtain authorization to operate (ATO) faster.
Change Management
“Culture eats strategy for breakfast.” - Peter Drucker
Change management directly relates to two of the Zero Trust guiding principles:
- Breaches Happen
- Ensure the Tone from the Top
In the context of enterprise transformation, resiliency is not merely the ability to withstand disruption. It is the capacity to adapt, recover, and thrive amid continuous change, hence the need for Change Management. Change Management (CM) is defined by Prosci as, “the application of a structured process and set of tools for leading the people-side of change to achieve a desired outcome.” CM is designed to help account for both the technical and organizational aspects of a solution, product, process, and so on. In this section, we will share how both of these aspects factor into making sure resiliency is taken into account within an enterprise environment.
The connection between CM and Zero Trust is not initially intuitive. One deals with people and process, while the other is often assumed to cover the technology aspect of the solution. In reality, ZT is just as, if not more, focused on the people and process part of the overall equation. Being able to effectively deal with change within our environments leads to a more secure environment that is highly adaptive and full of the checks and validations that ZT is built on. Through that lens, we look at two specific aspects of CM:
- Organization CM: The who and how things are accomplished
- Technical CM: Often focused on the tactical side of information technology
Organizational CM
Organizational CM (OCM) addresses the who and how, ensuring that people and processes are aligned, engaged, and empowered. This people-centric approach is foundational to building a resilient organization by focusing on a number of different elements.
Leadership Alignment and Sponsorship
A key aspect of resilience is the alignment between the business strategy, the security architecture, and operations.
Resilient change requires visible, aligned leadership. OCM ensures that:
- Leaders are unified in message and action, reducing mixed signals
- Sponsors are actively engaged, not just supportive
- Managers are empowered as change agents, driving change through their teams
Strong leader presence during change boosts morale and accelerates adoption. This leader presence also provides a foundation for users to stand on when they perceive instability.
Process Integration: Institutionalizing Resilience
An essential aspect of resilience is the incorporation into business processes and workflows. For example, we know malicious actors are increasingly using social engineering to attack humans instead of technical controls. The attacks on help desks at major casinos in 2024 are prime examples. Help desk workflows are being updated to better detect and thwart social engineering attacks.
The key is to create a resilient, aware culture through a combination of training, enforcement, and consistent messaging at all levels of management, starting at the top. The focus on process helps to mitigate some of the most common risks to organizations, including the top three threats that business face today (as noted in the Verizon’s 2025 DBIR):
- Credential abuse
- Exploiting vulnerabilities
- Phishing
All of these vectors saw an increase year over year. For example, vulnerabilities had a 34% increase. This can be mitigated by simply having a well-defined process to resolve the problem before it becomes an issue. By focusing on the OCM integration of change readiness into business processes, we can achieve successes such as:
- Performance management systems that reward adaptability
- HR practices that assess change readiness during hiring and development
- Governance models that include people-impact assessments in decision-making
This process integration ensures that resiliency is not reactive but embedded in the operational fabric.
Communication: Creating Clarity Where There is Uncertainty
Effective communication is the cornerstone of resilient change. OCM ensures that communication is:
- Transparent: Communicating the rationale, benefits, and impacts of the proposed change(s) reduces the uncertainty and helps to build trust
- Timely: Proactive updates help entities anticipate and prepare for the change, which often helps to minimize resistance and confusion
- Two-Way: Feedback loops allow leadership to gauge sentiment, address concerns, and adapt messaging in real time. For this to be effective, there needs to be a way for people to provide the feedback in ways that would not result in any negative consequences
Through open communication, OCM can help to reduce uncertainty and enable faster recovery from disruptions. It also has the potential to allow people to air concerns that may not have come up in other planning discussions and avoid disruptions altogether.
Training and Enablement: Building Adaptive Capacity
Resilient organizations invest in continuous learning. OCM within an organization should include embedded training as part of its lifecycle to:
- Equip employees with the skills and knowledge needed to operate within the new environment
- Reinforce confidence and competence, reducing the anxiety caused by a potential failure
- Promote cross-functional agility, enabling teams to adjust roles or responsibilities as needed
This upskilling ensures that the workforce has a higher likelihood to absorb change and become more resilient without suffering from productivity loss.
One example of creating resilient organizations through continuous learning is to train and empower more capable and accountable Cyber Resilience Officers. The recent NIST NICE Framework update introduced a new Cyber Resiliency Competency Area (NF-COM-007), defining key tasks, knowledge, and skills for anticipating, withstanding, recovering from, and adapting to cyber disruptions. It moves beyond traditional recovery planning to include resilient architecture design, impact-tolerance setting, and continuous improvement (NIST NICE).
Training professionals on these skills is critical to meet growing regulatory and threat pressures, ensuring organizations can reduce impact from complex attacks and sustain essential operations. The Cyber Resilience Manifesto—a call for the community to speak the same language and terms when it comes to cyber resilience—outlines key accountabilities and skills needed for the workforce.
Culture and Mindset: Embedding Change as a Norm
Culture is the invisible infrastructure of resiliency. OCM helps shape a culture that:
- Normalizes change as a constant, not a disruption
- Encourages psychological safety, where employees feel safe to experiment, fail, and learn
- Recognizes and rewards adaptability, reinforcing desired behaviors
When change is embedded in the organizational DNA, employees are more likely to respond with agility rather than resistance. This in turn allows for quick adjustments to occur in the face of an issue, which further increases resilience capabilities.
Technical CM
“Both a cab and the CAB are designed to get you where you are trying to go.”- Kevin Dillaway
When we speak about the technical pieces of CM, there is often a formalized process that includes the review of changes that may occur within the environment and account for impacts of those changes. How this process is implemented varies widely based on the size, complexity, and roles within an organization and can involve a single point of contact or entire teams of individuals. For many enterprise organizations, this may take the form of a committee that includes individuals across multiple areas of the organization that can assess the impact of changes and approve them. This is often called a Steering Committee or Change Advisory Board (CAB). For this section, we are going to dive into more detail using the idea of a CAB, but the same learnings can be applied to other similar models.
CABs often play a crucial role in overseeing and approving changes to security policies and technologies. CAB can ensure that changes align with Zero Trust principles and enhance organizational resiliency without disrupting operations. This starts with some of the key responsibilities of the CAB:
- Review and Approval: Evaluate proposed changes to security measures and authorize implementations
- Risk Assessment: Assess potential risks associated with changes and recommend mitigation strategies
- Communication: Ensure effective communication of changes to all stakeholders and provide necessary training
These key responsibilities, when they align with Zero Trust, should validate that changes in the environment have the appropriate controls, processes, and communication to ensure Disaster Recovery (DR), Business Continuity (BC), and resiliency. When Change Management and the CAB invest in Zero Trust and resiliency measures, it can provide significant cost savings by preventing costly data breaches, reducing downtime, and avoiding regulatory fines. The CAB can be the speed bump or, in some cases, the stop sign for deployments to make sure that these things are being planned for and implemented.
Additionally, Change Management helps to deal with resistance to change. Change Management primes the environment and people to be ready for the changes, to understand the what, why, when, and how things will happen. It can also be leveraged to educate users about the changes and make sure that adoption and adherence to new policies and procedures are implemented within the documented guardrails.
Pairing Change Management with the Zero Trust Architecture strengthens risk management by minimizing the attack surface and ensuring robust defense mechanisms are in place. This approach detects and mitigates threats early, preserving business continuity by:
- Enhancing security posture and reducing vulnerability to cyberattacks
- Improving regulatory compliance and reducing risk of penalties
- Increasing stakeholder confidence and trust in the organization’s ability to protect sensitive data
- Long-term cost savings through reduced incident response expenses and prevention of data breaches
The CAB is the gatekeeper for change. It ensures the organization maintains the integrity and resiliency of the environment during change. In conclusion, integrating Zero Trust Architecture with Change Management significantly enhances organizational resiliency, ensuring robust defense against evolving cyber threats and safeguarding business operations and assets.
Resilience Planning
The core of operational resilience planning is clarity of purpose. “Begin with the end in mind” is a transformative principle in Zero Trust; it compels leaders to clearly articulate what “resilient” means for the organization. This involves identifying critical assets and services, as well as establishing recovery objectives, business continuity thresholds, and stakeholder expectations. The core elements are found in the BIA.
Questions to anchor planning:
- Which business services are truly mission-critical?
- At what level of disruption are operations considered nonviable?
- How will we measure success in response, recovery, and adaptation?
By focusing on outcomes, organizations can build resilience strategies that are purposeful and tailored to organizational risk profiles.
Operational resilience is achieved through intentional design choices that ensure services remain available, recoverable, and adaptable under adverse conditions. Resilience planning must be outcome-focused, informed by the BIA, and embedded across technology, process, and operational practices. The objective is to ensure that critical business services can continue to function—at acceptable levels—even during system failures, cyber incidents, provider outages, or large-scale disruptions.
Resilient systems are designed to be loosely coupled, fault tolerant, globally distributed, and provider-diverse, minimizing single points of failure and enabling rapid recovery.
Assume Incidents will Occur
Zero Trust’s foundational precept of “never trust, always verify” is rooted in the assumption that adversaries will eventually penetrate defenses. Planning for resilience means designing systems and processes that operate on the assumption of compromise and that can limit, contain, and rapidly recover from such scenarios.
Comprehensive Architecture and Robust Capabilities
Building resilience requires distributed enforcement across multiple policy decision and enforcement points across the different pillars of Zero Trust, each reinforcing the others. Architecturally, Zero Trust emphasizes a number of key concepts to be applied across the organization’s technology stack, including continuous, context-aware verification of identity, dynamically adaptive least privilege access management, and microsegmentation. Operational resilience benefits from a multi-faceted, full stack Zero Trust approach, and incorporates comprehensive monitoring, AI-enabled incident detection and response, data protection, and robust, rapid recovery methods (e.g. an agentic SOC). The Zero trust model is: assume breach, assume the network is hostile, and gate every transaction on continuous, context-aware verification — regardless of where the request originates.
If an attacker does penetrate multiple defenses in a Zero Trust environment, the blast radius (scope of impact) is reduced. Some organizations find that a major, near term benefit of a full stack, microsegmented Zero Trust strategy and robust operational implementation is an enhanced capability to identify, assess, and rapidly remediate vulnerabilities and incidents, while minimizing their overall impact.
When it comes to resilience, it’s important to recognize defenses are no longer primarily technical. What’s required is a holistic, coordinated collaboration between technical, process, people, and organization defenses across the full cyber lifecycle of protect, detect, and recover.
Resilient Design Principles
To meet availability and continuity expectations identified in the BIA, systems must consistently apply the following design principles:
-
Loosely Coupled Services
- Minimize hard dependencies between components
- Use asynchronous communication and event-driven patterns where possible
- Enable independent deployment, scaling, and recovery
-
Redundancy by Design
- Eliminate single points of failure across application, data, and infrastructure layers
- Use active-active or active-standby deployments based on service criticality
- Ensure redundancy spans multiple fault domains and geographic locations
- Redundancy must apply not only to production workloads but also to supporting services essential for recovery and operations
-
Multi-Provider Strategy for Critical Services
- Use multiple authoritative DNS providers to prevent global name-resolution failures
- Avoid exclusive reliance on a single cloud, identity, or control plane service for critical operations
- Design failover paths that do not depend on the same provider or region
-
Diversified Network Connectivity
- Implement multiple, independent connectivity paths to cloud and datacenter environments
- Ensure physical and logical path diversity for private and public network connections
- Avoid shared infrastructure dependencies that could lead to correlated failures
-
Global Distribution
- Deploy services across multiple regions to withstand localized outages
- Replicate data according to regulatory, latency, and recovery requirements
- Support region-level isolation and independent recovery during large-scale disruptions
-
Strong Break-Glass Access Mechanisms
- Establish hardened, offline-capable break-glass accounts for emergency access
- Protect break-glass credentials using hardware-backed security (e.g., HSMs, secure vaults, physical escrow)
- Enforce strict audit logging, time-bound access, and post-incident review for all break-glass usage
- Ensure break-glass access is independent of primary identity providers where possible
-
CI/CD and Pipeline Resilience
- Maintain the ability to deploy and rollback applications using alternative or offline mechanisms
- Retain signed build artifacts and infrastructure templates outside of the primary CI/CD platform
- Support manual or secondary pipeline execution during prolonged outages of primary CI/CD services
-
Code Repositories
- Maintain read-only mirrors or replicated backups of critical source code
- Ensure access to versioned release artifacts independent of the primary repository provider
- Protect repository access using independent authentication paths where possible
-
Secrets Management
- Replicate secrets securely across multiple regions or platforms
- Support emergency recovery access to critical secrets using isolated and audited mechanisms
- Ensure secrets remain accessible even if the primary management service is unavailable
-
Identity and Access Management Services
- Design highly secure identity architectures with phishing-resistent MFA, redundancy and federation across providers wherever feasible
- Maintain emergency authentication paths for critical administrative access
- Ensure production workloads can continue operating during partial identity service outages
Agility and Continuous Adaptation
The threat landscape is fluid. By definition, threats evolve. Resilient organizations embrace change—reviewing, testing, and updating controls and playbooks in anticipation of new risks. Zero Trust Architectures are inherently adaptable; they can be incrementally deployed and refined as the environment evolves.
Stakeholder Engagement
Resilience is not a siloed responsibility. It demands collaboration across the enterprise, from executive leadership to operations teams, vendors, and regulators. Engaging stakeholders early and often fosters shared understanding and coordinated action during crises.
Resiliency Testing / Chaos Testing
Testing verifies that a system meets its functions and non-functional requirements. Resilience testing explicitly evaluates the system’s capacity to withstand, adapt to, and recover from unexpected disruptions or failures, all within established boundaries. These boundaries are usually defined in the BIA or similar documents approved by senior leadership.
Resilience testing distinguishes itself from other methods by employing scenarios, focusing on specific component assessments, and simulating disruptions from external sources. Although physically removing key components or disrupting third-party connections might not always be feasible, we can develop tests that mimic these scenarios, allowing us to gather concrete results.
Full-scale scenarios are not always practical to exercise. Full-scale scenarios are normally expensive, expansive, and disruptive. Instead, full-scale scenarios can be decomposed into parts, and exercised separately. When deficiencies are detected, the appropriate players are alerted, and the resilience team monitors to ensure the deficiencies are addressed.
Zero Trust Foundational Concepts for Resilience Testing
This resilience testing framework operationalizes the seven themes common to Zero Trust , providing strategic guidance for developing comprehensive, sustainable, and effective chaos testing capabilities within modern Zero Trust Architectures.
Assume Breach
Zero Trust resilience testing assumes every testing environment and scenario is already compromised, constantly challenging trust assumptions across all system components. This approach drives chaos testing scenarios that assess whether segmentation, micro-segmentation, and least privilege controls can effectively contain cascading risks and limit potential damage even during multiple simultaneous failures. The testing scenarios validate that breach containment mechanisms work effectively when attackers are assumed to have network presence, aligning with the Zero Trust principle that organizations must reduce implicit trust and prevent lateral movement at all levels.
Explicit Verification
During resilience testing, recovery options, failover procedures, and response actions must be authenticated and authorized immediately, with ongoing risk evaluation throughout chaos events. This principle ensures that authentication, authorization, and validation happen at every stage, as systems enter or exit failure states, using multiple contextual signals like identity, device status, location, and behavior trends. Testing scenarios must confirm that policy enforcement points (PEPs) automatically respond to changing contexts and that dynamic access controls maintain secure access during disruptions, replacing informal verification with systematic, measurable requirements.
Enforce Least Privilege
Resilience testing scenarios confirm that access is limited to what’s necessary during failures and recovery. The tests show that break-glass access procedures follow least-privilege principles while allowing for emergency responses, proving that privilege escalation is prevented during chaotic events and that emergency access is both controlled and audit-ready. This involves verifying that privileged access management (PAM), just-in-time provisioning, and regular access reviews keep working effectively under stress, so each person, device, or application gets only the access they need for the shortest time.
Iterative and Incremental (Journey)
Resilience testing programs are rolled out as multi-year, phased transformations rather than single projects. This approach starts with small-scale chaos testing scenarios that target the most critical risks or high-impact opportunities to get quick results. As the testing complexity and coverage grow over time, scenarios are broken down into smaller, manageable units when full end-to-end testing isn’t practical. Transitions between parts are exercised and verified incrementally. This way, teams can make steady progress in building resilience capabilities without overwhelming their operations. Regular feedback helps refine the approach as new threats, lessons, and technologies emerge.
Nondisruptive
Business operations are top priority during resilience testing. Use chaos testing to get the most out of resilience validation without disrupting daily operations. To ensure success, use proof-of-concept and pilot testing to let teams validate their test setups, scenarios, and response procedures in a controlled setting before scaling up. This approach helps organizations fine-tune their testing methods, tackle operational issues early, and build trust with stakeholders in their resilience capabilities as part of a deliberate transformation.
Start with What You Have
Our resilience testing capabilities are built on top of existing tech and processes, gradually adding Zero Trust-aligned chaos testing. We start by pinpointing and validating the most critical assets within our “protect surface”—the key data, apps, assets, and services that keep the business running and meeting regulatory requirements. We use our current monitoring systems, incident response workflows, and testing frameworks wherever we can, expanding their capabilities through a Zero Trust lens to meet resilience requirements without replacing infrastructure, which speeds up progress while keeping costs in check.
Antifragile Evolution
Resilience testing scenarios transform controlled failures into capability enhancements, rather than simply validating recovery. This approach leverages chaos engineering to create systems that become more secure, efficient, and adaptive as a direct result of testing stress and adversity. Each chaos test becomes a learning opportunity that enhances AI-driven security models, refines policy enforcement points, and strengthens interconnected Zero Trust controls. The antifragile methodology ensures that Zero Trust implementations not only withstand attacks and failures but also capitalize on disruptions to evolve stronger defensive mechanisms, more sophisticated threat intelligence, and more adaptive response capabilities, while maintaining the foundational principles of explicit verification, least privilege, and breach assumption.
Integration with Zero Trust Pillars
These foundational principles ensure that resilience testing comprehensively addresses all Zero Trust pillars—User/Identity, Devices, Applications and Workloads, Data, Network/Environment, and the two sets of cross-cutting capabilities Automation and Orchestration, and Visibility and Analytics. The goal is to create a holistic approach to testing that validates interconnected Zero Trust capabilities across technology, processes, personnel, and third-party ecosystems.
Zero Trust boosts resilience testing by building assurance into every interaction. With the Explicit Verification principle, no user, device, workload, or application is automatically trusted. Instead, authentication, authorization, and ongoing validation happen at every stage. This approach enables chaos testing by constantly verifying and temporarily authorizing all recovery options, failover procedures, and response actions whenever the system enters or leaves failure states.
Moreover, Assume Breach suggests that attackers may already be inside the network. As a result, resilience testing should evaluate whether measures such as segmentation, micro-segmentation, and least privilege controls can effectively mitigate cascading risks, thereby limiting the potential impact even in the event of multiple failures simultaneously.
Finally, because all communication is secured and data sources are considered resources, chaos testing should assess resilience not just at the infrastructure level but also across each layer of the Data, Applications, Assets and Services (DAAS) stack, including applications, APIs, machine learning endpoints, and vendor-influenced workloads.
Unlike traditional testing, which typically evaluates control effectiveness in isolation, resiliency testing verifies whether interconnected Zero Trust controls, encompassing technology, processes, personnel, and third-party ecosystems, actually provide assurance. Chaos testing applies Zero Trust principles to simulate major failures, such as credential compromises, key staff shortages, network degradation, or widespread outages of third-party services. This process requires organizations to demonstrate both theoretical preparedness and the ability to recover.
Our flexible, framework-neutral approach utilizes asset visibility, dynamic data flow mapping, automated risk detection, and real-time evidence collection to verify compliance with standards such as ISO/IEC 27001, NIST CSF, HIPAA, PCI DSS, DORA, and ORF, while also supporting Zero Trust principles. Resiliencies confirmed through chaos testing are built into the feedback loop, boosting organizational readiness and reinforcing Zero Trust enforcement.
Resilience testing requirements exist primarily within regulatory frameworks governing specific industries and sectors. Only four frameworks, the 2025 HIPAA Security Rule, GLBA, PCI DSS v4.0, and DORA, mandate explicit resilience testing with defined frequencies and methodologies. Additional frameworks including CISA Zero Trust Maturity Model (ZTMM), NIST SP 800-207, Department of Defense Zero Trust Reference Architecture, ISO/IEC 27001:2022, ISO 22316:2017, the Operational Resilience Framework, and NIST Principles and Objectives.
End-to-End Scenario-Based Validation
Companies should create complex, multi-stage scenarios that mirror real-world adversarial events. For instance, launching simultaneous ransomware attacks, supply chain disruptions, and upstream cloud provider outages can test the effectiveness of “assume breach” strategies under pressure. Detailed Data Flow Diagrams (DFDs) can expose dependency chains, identifying chokepoints and individual vulnerabilities.
These scenarios evaluate whether we meet the Minimum Viable Service Levels(MVSLs) and confirm that recovery actions stay within regulatory limits. The results should verify system recovery and clearly show how recovery measures align with Zero Trust policies, including dynamic access control, PEP enforcement, and continuous monitoring.
Continuous Asset and Threat Surface Awareness
Continuous Attack Surface Management (ASM) keeps all DAAS assets, including approved applications, shadow IT, APIs, and ML endpoints, mapped and visible. Following Zero Trust principles, we consider all data sources and computing services as resources. So, having an updated dependency record ensures our resilience testing covers both known and hidden vulnerabilities.
Companies using BIA-driven prioritization should still check dependency chains for hidden systemic risks. Even if they don’t aim for full coverage, sectors crucial to business operations must undergo Zero Trust resilience tests, with a focus on dependencies that might bypass standard visibility tools.
Empirical Control Effectiveness
Before starting resilience testing, traditional testing can validate the effectiveness of security controls. Resilience testing takes this a step further by confirming that these controls deliver the Zero Trust outcome in real-world conditions.
In other words, resilience testing goes beyond simply asking, “Does the firewall block traffic?” and instead investigates:
- Did segmentation reduce blast radius during cascading failures?
- Did least privilege access prevent privilege escalation during chaos?
- Did the system dynamically revoke or rotate credentials under stress?
- Were break-glass accesses both controlled and audit-ready?
- Did policy enforcement points (PEPs) respond automatically to changing context?
By incorporating metrics such as Hard Restart Recovery Time, Modularity, and Stress Testing Vibrancy, our testing demonstrates that Zero Trust enforcement is effective in real-world situations. These metrics provide concrete evidence to support audits and offer the board some reassurance.
Organizational, Third-Party, and Ecosystem Integration
Real resilience can’t be shown in a vacuum. Organizations need to assess not only their internal ability to recover but also the broader effects of losing a key service provider or a crucial upstream supplier.
Testing needs to verify if we can still meet our MVDOs, even if CSPs fail, SaaS providers go out of business, or external payment services shut down during peak hours. From a Zero Trust perspective, adaptive access controls and ecosystem integrations should continually verify access and minimize damage, even if trusted vendors cannot.
Resiliency testing involves collaboration with partners across legal, compliance, vendor, and sector groups. By working together with industry peers and critical infrastructure communities, organizations can build an ecosystem-based approach that views resilience as a shared effort, rather than a series of separate tasks.
Immutable Audit and Evidence Engine
One of the core Zero Trust principles is to Continuously Monitor, which is achieved in part through resiliency testing. Every chaos event generates unalterable, audit-ready logs, test results, compliance mappings, and remediation artifacts, all of which are kept for regulatory review and audit purposes.
Dashboards display key indicators such as MTTD/MTTC, impact thresholds, and stress test coverage. Logs must be centralized, immutable, and analyzed not only for compliance purposes but also for real-time investigations. This approach is crucial for governance, regulators, and executives to maintain trust through transparency and technical assurance.
Continuous Feedback, Engineering, and Policy Loop
Every resilience exercise presents an opportunity to enhance the enforcement of policies in real-time. When failures, limitations, or weaknesses show up under stress, they’re not the end of the story. Instead, they spark updates to the architecture, such as re-engineering with modular designs, better segmentation, revised vendor contracts, or new failover strategies.
At its core, this feedback loop is the defining characteristic of a living Zero Trust Architecture. It’s not fixed—it constantly adjusts to keep up with changing threats, evolving regulatory standards, and increasing sector-wide risks.
Methodologies and Approaches
Advanced Chaos and Resilience Scenario Testing
Companies should assess not only individual control failures but also complex, interconnected crises. For instance, scenarios like insider sabotage paired with a SaaS outage, a failed SSO/IDP chain combined with a compromised supply-chain API, or the loss of key personnel during system degradation. Each case should be directly linked to Zero Trust principles, demonstrating that privileges are constantly reviewed, communications stay encrypted, and anomalies trigger access quarantine.
Asset Discovery, Dependency, and Privilege Mapping
Continuous ASM, dependency mapping, and federated CMDBs ensure that all data sources are treated as resources. This level of detail allows scenario creation, enabling testers to pinpoint common risks, assess subsystem independence, and confirm whether modular engineering reduces systemic failures.
Automated Enforcement, Remediation, and Testing
Automation is crucial. To achieve Zero Trust resilience, we need fast, machine-driven responses: PEPs quickly revoke access, Security Information and Event Management (SIEM)/Security Orchestration, Automation, and Response (SOAR) isolates compromised nodes, and credential updates occur instantly. While manual playbooks provide a backup plan, automation remains the primary priority.
Expanded Top-Level and Lower-Level Scenarios
Here are detailed IT and cybersecurity-focused scenarios that show how Zero Trust principles are tested through chaos testing. These scenarios are designed to be relatable, technically sound, and relevant to real-world operations.
Scenario 1: Cascading Identity Provider (IdP) Outage and Credential Compromise
- IdP failure blocks the authentication system-wide.
- Users flood the system with retries, spikes observed in failed login logs.
- Simulation injects compromised credentials, anomalies caught by continuous monitoring.
- Break-glass access activated with least-privilege and full audit measures.
- Validates “never trust, always verify” and “assume breach” while confirming that recoverability is possible within MVDO timelines.
Scenario 2: SaaS API Dependency and Malicious Data Injection
- SaaS provider API sends manipulated data.
- Monitoring flags anomalies, policy enforcement points throttle risky sessions.
- Session quarantined, credentials rotated, API allowlist enforced.
- Business continuity operations shift to cached or alternate API.
- Validates all communication secured, dynamic enforcement, and immutable logging.
Scenario 3: Ransomware Spread Across Hybrid Environments
- Ransomware encrypts on-prem shares, spreads toward cloud workloads.
- Micro-segmentation blocks lateral movement.
- Compromised sessions are revoked dynamically, and integrity checks ensure quarantine.
- Failover shifts to clean cloud workloads with MVDO preservation.
- Validates segment and contains blast radius as Zero Trust outcome and empirical control effectiveness.
Scenario 4: DDoS Against Critical Business Application Stack
- Surge overwhelms the external-facing portal.
- Traffic verified dynamically; malicious sessions throttled.
- Step-up authentication blocks inbound suspicious traffic.
- Load shifted to alternate infrastructure providers.
- Validates containment of customer impact and Zero Trust resilience of external communication gateways.
Scenario 5: Insider Threat with Elevated Privilege Abuse
- Insider attempts sensitive data extraction.
- Adaptive Zero Trust analytics detect anomalous behavior.
- Mid-session credential revocation cuts off the insider.
- Access restored only under auditable break-glass procedures.
- Validates least privilege and continuous monitoring principles.
Scenario 6: Multi-Cloud Service Provider (CSP) Outage
- Primary CSP suffers a regional outage.
- Failover triggers a secondary CSP under throttle simulation.
- Prioritized MVDO workloads maintained; ancillary workloads scale down.
- Contract overcommitment risk verified in practice.
- Validates ecosystem resilience and least-privilege during constrained access conditions.
Scenario 7: Compromised Endpoint with Shadow IT Exposure
- Remote device compromised, endpoint integrity check fails.
- Session tokens revoked immediately.
- Attempted shadow IT SaaS access blocked proactively by adaptive controls.
- SOC automation triggers reset and device lockout.
- Validates Zero Trust visibility across sanctioned and unsanctioned resources.
Scenario 8: Supply Chain Cascade Failure
- A critical fourth-party supplier suffers a ransomware attack.
- Your direct SaaS vendor encounters unexpected service disruptions.
- Your monitoring systems detect a drop in inbound data quality and failed integration jobs across business applications.
- Escalation playbooks are activated; IT and OR teams notify impacted business units.
- Incident response triggers alternate data sources and redirects key workflows.
- Validates supply chain dependency mapping, escalation paths, and failover plans meet regulatory and resilience objectives.
Best Practice Metrics and Reporting
Track sector-leader metrics:
- Mean Time to Detect/Contain (MTTD/MTTC)
- Hard Restart Recovery Time
- Inventory Completeness
- Stress Testing Vibrancy
- Incident auto-remediation %
- RTO/RPO attainment
- Bounded impact/severity, modularity, and blast radius containment
Use dashboards for executive- and board-level attestation, as well as for sector benchmarking. Metrics must align with both frameworks and Zero Trust principles.
Preserving All Evidence and Radical Transparency
Every log, test result, configuration change, and post-mortem report is kept in a durable format. Major test failures and systemic gaps are promptly escalated to leadership and shared as necessary, demonstrating the organization’s commitment to complete transparency and trust with regulators.
Implementation steps:
- Mapping and Indicators: ASM and CMDB maintain always-current DAAS dependencies
- MVDOs and Prioritization: Board defines sector-relevant MVDOs
- Orchestrated Testing: Multi-threaded chaos across layers, aligned to Zero Trust
- Review and Train: Every test closes with redesign, re-training, and modular adjustments
- Executive Accountability: Leadership attests directly to resilience gaps and posture
Outcomes and benefits:
- Audit-ready resilience validated life, not just in checklists
- Operational risk reduced by limiting systemic blast radius
- Regulatory and customer confidence bolstered through transparent evidence
- Faster response time, reduced fatigue, streamlined recovery cycles
- Cross-organizational trust enforced through proof, not assumptions
When resiliency testing is driven by Zero Trust and powered by continuous automation, advanced scenario testing, and audit-grade evidence, it becomes the operational backbone of adaptive enterprise resilience. This approach turns resilience into a living assurance that’s constantly tested, improved, and verified—making it a key part of Chaos Engineering.
Monitoring and Alerting
Monitoring and alerting directly align with the Zero Trust guiding principle of continuous monitoring and the BIA.
Monitoring and Alerting Scenarios
Let’s understand the context—from examples and scenarios of monitoring and alerting in Zero Trust environments and from both technical and business use cases relevant to enterprise resilience.
-
Insider Threat Monitoring Scenario: An employee from the finance department accesses sensitive records from their usual device and location. During the session, an anomalous IP address is detected (sudden change to a foreign country). In a Zero Trust environment, the location change is recognized as a potential account hijack and automatically terminates the session, sending a high-priority alert to the security operations team for review
- Outcome: Continuous verification throughout the session and location-based monitoring instantly detect compromised accounts
-
Data Exfiltration Detection Scenario: A user downloads an unusually large volume of sensitive data outside of standard working hours. The system’s behavioral analytics engine flags this pattern as suspicious since it exceeds established baselines for that role. An automated alert is generated, access to further data is restricted, and the SOC investigates for potential insider threats or the presence of malware
- Outcome: Anomaly detection and behavioral baselining underpin Zero Trust alerting, preventing large data loss by rapid response
-
Supply Chain Monitoring Scenario: A global manufacturer uses AI-enabled event monitoring to track thousands of suppliers worldwide. The system continuously ingests news and IoT sensor data. Upon detecting a fire at a critical supplier’s plant (picked up from news feeds), the AI platform sends a real-time alert directly to procurement and operational heads. This triggers supply chain contingency plans, such as rerouting orders and accelerating alternative sourcing to maintain service levels
- Outcome: Early-warning monitoring of third-party events enables coordinated, cross-functional responses to external risks
-
Role-Based Access Violation Scenario: An HR employee attempts to access financial records, which falls outside their role-based access permissions per Zero Trust policy. The Zero Trust access control system immediately blocks the request and generates an alert for the SOC to review and document a potential policy violation or compromised account
- Outcome: Least-privilege enforcement is actively monitored, and every access attempt is assessed in context
SOC Alert Scenarios
-
Security Breach: Unauthorized login detected from an unrecognized device or country triggers a high-priority alert. Rapid containment is initiated (e.g., account lockout)
-
Vulnerability Detected: New zero-day exploit is identified affecting production servers. Automated patching is queued and critical alerts go to the vulnerability management team
-
System Failure: Cloud SIEM detects a mission-critical database offline; the incident is escalated to both IT operations and business continuity teams
-
Compliance Violation: Attempted transfer of regulated data to unauthorized external storage is flagged, blocked, and reported to compliance teams for audit trail completion
-
Phishing Detected: Endpoint Detection and Response (EDR) detects phishing email and quarantines after delivery; incident is escalated to SOC who investigate and block further occurrence
Table 2 provides examples of monitoring, alerting and outcomes by industry.
Select Example Monitoring and Alerting with Outcomes by Industry
| Industry | Monitoring and Alerting Example | Outcome |
|---|---|---|
| Healthcare | Unusual access to medical records triggers immediate alert/lockout | Patient data protected |
| Finance | Access from new, unmanaged device to core banking system detected | Session blocked, fraud reviewed |
| Manufacturing | Factory IoT sensor indicates abnormal equipment behavior | Site ops alerted, production halt prevented |
| Education | Student attempts to access restricted staff records | Access denied, activity logged |
Table 2.
Concepts in Monitoring and Alerting
Monitoring and alerting are critical pillars for achieving resilience and operational integrity in a Zero Trust enterprise environment, ensuring rapid detection, containment, and recovery from incidents, disruptions, or regulatory noncompliance.
In a Zero Trust resilient enterprise, monitoring and alerting must integrate technical, operational, and supply chain considerations, moving beyond compliance to deliver measurable, actionable resilience at scale.
The following sections outline actionable content, best practices, and guidelines for effective monitoring and alerting within this context.
Alignment with Zero Trust and Resilience Objectives
Continuous monitoring turns the static security perimeter into a dynamic security mesh that adapts to evolving threats, business requirements, and operational disruptions. It provides the evidence needed for compliance with regulatory mandates such as DORA and supports maintaining minimum viable service levels (MVSLs) even under active attack or disruption. By doing so, it not only reduces the impact of incidents but also ensures that monitoring insights directly inform and improve policy enforcement, incident response, and organizational learning.
Continuous monitoring is both a guiding principle and a daily practice that empowers organizations to move from reactive defense to predictive resilience—fulfilling Zero Trust and resilience mandates in a measurable, auditable, and actionable manner.
Continuous monitoring is a foundational guiding principle within Zero Trust and resilience frameworks, ensuring that organizations maintain a proactive, real-time security posture across users, devices, data, and dependencies. Continuous monitoring is not simply a technical capability—it is an operational mindset embedded in Zero Trust architecture and a key enabler of enterprise resilience. This principle dictates that all assets, transactions, user behaviors, and interconnections must be subject to ongoing, automated observability. Rather than relying on periodic audits or manual checks, organizations shift to real-time surveillance, ensuring the earliest possible detection of threats, misconfigurations, and failures.
Core objectives:
-
Immediate Threat Detection: Identify adversarial activity, policy violations, and emerging vulnerabilities before they inflict harm, minimizing dwell time and the blast radius within and beyond enterprise boundaries
-
Continuous Asset Posture Assessment: Dynamically evaluate the configuration, health, and security status of devices, identities, applications, and services at all times, rather than relying on static controls or periodic assessments
-
Proactive Policy Enforcement and Adaptation: Feed live telemetry into policy engines to enable just-in-time access decisions, rapid privilege revocation, and adaptive segmentation as risk factors or environmental conditions change
-
Supply Chain and Third-Party Oversight: Apply continuous monitoring across not just internal environments but the extended supply chain—tracking vendor activities, service integrity, and compliance to reduce systemic vulnerabilities
Practices for implementing continuous monitoring:
- Unified Telemetry Collection: Use a centralized platform (e.g., SIEM, SOAR, modern cloud-native analytics) to aggregate logs, endpoint events, network flows, API calls, and user actions across the environment—including SaaS, IaaS, on-premises, and OT/IoT domains
- Behavioral and Anomaly Analytics: Leverage User and Entity Behavior Analytics (UEBA) and machine learning to detect deviations from baseline behaviors or known-good patterns, enabling the detection of novel threats and insider risks
- Automated Alerting and Response: Integrate monitoring solutions with automated playbooks that can trigger immediate containment (e.g., isolating compromised accounts or segments) when malicious activity is confirmed—reducing manual response lags
- Real-Time Posture Assessment: Employ continuous device, application, and cloud security posture management tools that dynamically detect misconfigurations, outdated software, or non-compliance with organizational policies
- Visibility into Shadow IT and Orphaned Assets: Implement attack surface management platforms to discover, inventory, and monitor assets that may fall outside normal IT management—reducing blind spots and unmanaged risk
- Test and Validate Controls Regularly: Use breach and attack simulation (BAS), chaos engineering, and red/purple teaming in an ongoing fashion—not just during annual exercises—to verify not only that controls exist, but that monitoring detects and responds to real-world scenarios
- Immutable and Auditable Logs: Maintain logs in an immutable, tamper-evident manner to support forensic analysis, regulatory requests, and supply chain transparency
Key metrics for continuous monitoring:
| Metric/KPI | Rationale |
|---|---|
| Mean Time to Detect (MTTD) | Indicates how quickly threats are identified via continuous telemetry |
| Coverage of Monitored Assets (%) | Demonstrates the breadth of real-time surveillance, including third-party systems |
| Number of Policy Adaptive Events | Measures how often policies are automatically adapted in response to live monitoring data |
| Unmonitored Asset Detection Rate | Tracks discovery and onboarding of previously unmanaged assets |
| Incident Response Automation Rate (% incidents auto-contained) | Reflects how often continuous monitoring directly triggers automated containment or remediation actions |
Table 3. Key Metrics for Continuous Monitoring
Effective Monitoring and Alerting
To evaluate the effectiveness of Zero Trust monitoring, organizations should track a blend of security, compliance, operational, and business impact metrics. Effective measurement ensures continuous improvement, demonstrates value to stakeholders, and provides actionable insights for both security teams and executive decision-makers.
Monitoring and Alerting Best Practices
- Continuous Telemetry Collection: Integrates user, device, application, and network activity to detect blast radius changes or lateral movement
- Alert Prioritization and Triage: Depend on risk scoring, context, and real-time collaboration between security and operations teams before escalation to incident response
- Automated, Scenario-Based Simulation: Helps validate alert fidelity for both common and “black swan” events, ensuring resilience testing remains actionable and realistic
Effective monitoring and alerting weave Zero Trust principles into operational resilience, making incidents easier to detect, isolate, and recover from in real-world, high-stakes environments.
Incident Detection and Response
Incident detection and response directly aligns with the Zero Trust guiding principle of Breaches Happen.
Resilience and Zero Trust are designed to reduce the likelihood of incidents and the blast radius (impact), allowing us to detect faster and recover quicker. Resilience places increased importance of including third parties in tabletops and the inclusion of third parties in Incident Response (IR). The BIA provides recovery priorities along with insight into the order of recovery.
Incident response (IR) is a critical component of enterprise resiliency and an essential element in operationalizing the Zero Trust principles. Incident response directly supports resiliency and Zero Trust by providing a structured approach to detect, contain, eradicate, and recover from security incidents. A well-defined IR plan ensures that when an incident occurs, the organization can maintain critical operations, minimize downtime, and potentially reduce financial and reputational damage. This is due to both resilience and Zero Trust being built around limiting the ability for incidents to occur. If there is an incident, they both help to lessen any potential impact and be able to respond quicker.
Key aspects of resiliency supported by IR include:
- Improved detection and containment to prevent lateral movement and data exfiltration
- Clear communication channels to coordinate internal teams and external stakeholders
- Post-incident analysis to identify root causes and strengthen defenses
Principles of Zero Trust enhance IR by having organizations focus on things that will not only provide faster response times, but also force automation. These can include things like:
- Granular access controls to limit the blast radius of a compromised account or device
- Real-time analytics and behavioral baselines enable faster identification of suspicious activity
- Automated policy enforcement can isolate affected assets without manual intervention, accelerating containment
To achieve resiliency, organizations should integrate IR planning into their Zero Trust strategy. This process should include:
- Developing playbooks that leverage Zero Trust controls during incident handling
- Incorporating threat intelligence and continuous risk assessment into IR workflows
- Regularly testing and updating IR plans through tabletop exercises and simulations that reflect Zero Trust environments
By embedding Zero Trust principles into incident response, enterprises increase the chance to prevent and detect threats, and accelerate recovery and adaptation when incidents occur. This integration transforms security from a reactive function into a proactive process and set of controls to provide business continuity and resilience.
When it comes to IR, it is important to remember the saying, “Never let a good crisis go to waste.” This is especially true for security incidents due to the fact that by investigating them, organizations can close loopholes, fix vulnerabilities, and minimize impact from similar incidents happening again. Additionally, reporting requirements outlined by CISA help other organizations learn from the information of other breaches to protect and strengthen their own systems and processes. This helps to provide an open-source feedback loop to benefit the entire industry and define best practices and recommendations.
A robust incident response plan is critical for addressing data breaches or security incidents effectively. This plan should outline procedures for identifying, containing, and eradicating threats, as well as recovering affected systems and data. Regular testing and updating of the incident response plan ensure preparedness for various scenarios. Collaboration with legal, communications, and compliance teams is necessary to manage the aftermath of an incident and maintain stakeholder trust.
In September 2025, CISA released an Incident Response advisory regarding lessons learned. The advisory recommends that organizations incorporate the following in their plans. These also apply directly to steps 3, 4, and 5 of the five-step Zero Trust process:
- Prioritize Patch Management: Expedite patching of critical vulnerabilities, particularly those listed in CISA’s Known Exploited Vulnerabilities catalog, with a focus on public-facing systems
- Strengthen Incident Response Plans: Regularly update, test, and maintain incident response plans, ensuring they include procedures for engaging third-party responders and deploying security tools without delay
- Enhance Threat Monitoring: Implement centralized, out-of-band logging and ensure SOCs continuously monitor and investigate abnormal network activity to detect and respond to malicious activity effectively.
In March 2022, the Cyber Incident Reporting for Critical Infrastructure Act of 2022 (CIRCIA) was signed into law. Among other things, CIRCIA requires CISA to develop and implement regulations requiring covered entities to report covered cyber incidents and ransomware payments to CISA, thereby allowing CISA to rapidly deploy resources and render assistance, assess impact across sectors, and quickly share information with defenders to reduce contagion.
Zero Trust Five-Step Implementation Process for Resilience
“Trust is a human emotion, not a security control.” - John Kindervag
Zero Trust has gone from being a security trend to a core principle for both businesses and governments. Now, agencies, critical infrastructure, and private organizations are dealing with persistent, well-funded attackers who can easily get past traditional defenses. As a result, resilience has become a key foundation. While cybercrime is unavoidable, minimizing downtime and disruptions to operations is crucial.
Regulations like the U.S. White House Executive Order 14028, OMB M-22-09, and the CISA Zero Trust Maturity Model mandate that US federal agencies put in place continuous verification and rapid recovery strategies.
These steps not only ensure compliance but also boost operational resilience and durability in the event of cyberattacks.
The Five-Step Zero Trust Implementation Lifecycle
The NSTAC Report to the President on Zero Trust and Trusted Identity Management outlines a five-step process for Zero Trust implementation that the Cloud Security Alliance (CSA) is elaborating detailed guidance for.
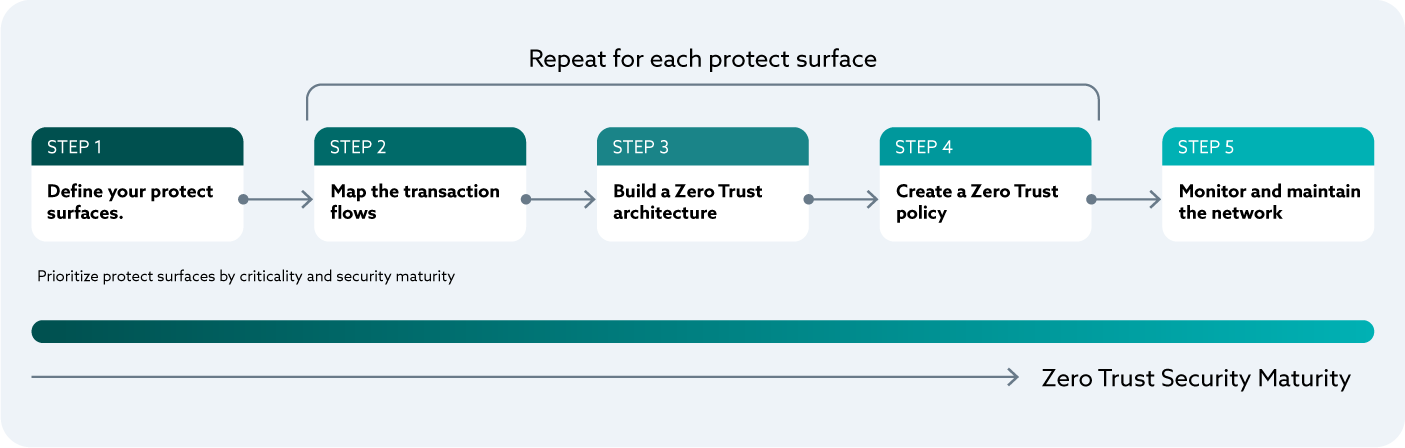
Figure 5. The CSA Five Step Zero Trust Implementation Process Illustration*
This control mapping framework works in conjunction with NIST SP 800-207 Zero Trust Architecture principles and the NIST Risk Management Framework (SP 800-37) to provide organizations with complementary approaches for achieving secure, compliant, and operationally resilient security postures.
The five-step Zero Trust implementation process has emerged as the predominant methodology across the cybersecurity community, endorsed by organizations ranging from NIST and CISA to the CSA and leading security vendors. This systematic approach transforms abstract Zero Trust principles into actionable implementation steps that organizations can execute incrementally. What follows is a comprehensive discussion of how this methodology can be integrated into your resilience program, extending beyond traditional cybersecurity to encompass business continuity, operational resilience, and regulatory compliance.
Unlike one-time security projects, this five-step framework establishes a continuous improvement cycle that adapts to evolving threats, changing business requirements, and emerging regulatory mandates. The methodology’s strength lies in its ability to align technical security controls with business objectives while maintaining the flexibility to accommodate organizations of varying sizes, industries, and maturity levels.
The CSA has developed comprehensive guidance for Zero Trust implementation through multiple authoritative resources that organizations can leverage:
-
CSA Defining the Zero Trust Protect Surface Guidance for Step 1
-
CSA Zero Trust Guiding Principles: This foundational document outlines the 11 core principles that inform effective Zero Trust strategies, providing vendor-neutral guidance applicable across industries
-
Certificate of Competence in Zero Trust (CCZT): The industry’s first authoritative Zero Trust certification program, developed in collaboration with John Kindervag and other Zero Trust pioneers, offers structured training aligned with the five-step methodology
-
Zero Trust Guidance for Critical Infrastructure: CSA’s specialized guidance for operational technology (OT) and industrial control systems (ICS), demonstrating how the five-step process applies to critical infrastructure environments
-
Zero Trust Working Group Publications: The CSA Zero Trust Working Group continues to develop standards for achieving consistency across cloud, hybrid, and endpoint environments, with ongoing research in automation, maturity models, and implementation best practices
These resources work together to support the five-step implementation approach, offering industry-specific guidance and professional development opportunities for Zero Trust practitioners. When implementing the methodology, organizations should refer to these CSA publications for in-depth technical guidance and alignment with industry best practices.
Zero Trust Five-Step Process and Guiding Principles
Our five-step Zero Trust implementation lifecycle aligns closely with guiding principles that come from industry best practices and government guidance.
The five steps are:
- Defining the Zero Trust Protect Surface
- Map the Transaction Flows
- Build a Zero Trust Architecture
- Create a Zero Trust Policy
- Monitor and Maintain the Network
Each step builds on specific principles while supporting the broader Zero Trust philosophy:
-
Begin With the End in Mind is deeply rooted in Step 1, Define the Protect Surface, where organizations pinpoint their top business priorities and link them to specific DAAS elements. This approach guarantees that Zero Trust implementation aligns with strategic business objectives, rather than becoming just a tech-driven project
-
Do Not Overcomplicate is the guiding principle behind the entire methodology, promoting gradual and manageable implementation phases. Instead of trying to make a complete overhaul all at once, the five-step approach divides the complex process of adopting Zero Trust into smaller, more manageable parts that can be built on top of existing security investments
-
Products are Not the Priority; this is reinforced throughout Steps 2-4, emphasizing that Zero Trust success depends on understanding workflows, designing appropriate policies, and integrating people and processes, not simply deploying new technologies. The methodology treats technology as an enabler of Zero Trust principles, not the solution itself
-
Access is a Deliberate Act is operationalized in Steps 3-4, where organizations architect explicit verification mechanisms and create policies that eliminate implicit trust. Every access decision becomes intentional, contextual, and continuously validated
-
Inside Out, not Outside In shapes the protect surface methodology in Step 1, focusing first on what must be protected rather than building perimeter defenses. This principle drives the DAAS-centric approach that characterizes modern Zero Trust implementations
-
Breaches Happen informs the resilience enhancements built into each step, particularly the monitoring and incident response capabilities in Step 5. The methodology assumes compromise and builds containment and recovery mechanisms throughout
-
Understand Your Risk Appetite guides the business impact analysis and prioritization activities in Steps 1-2, ensuring that Zero Trust investments align with organizational risk tolerance and compliance requirements
-
Ensure the Tone from the Top and Instill a Zero Trust Culture are addressed through the stakeholder validation and cross-functional workshop requirements embedded in each step, recognizing that technical controls alone cannot achieve Zero Trust objectives
-
Start Small and Focus on Quick Wins directly influences the implementation approach in Step 4, advocating for pilot programs and incremental deployment that demonstrate value while building organizational confidence
-
Continuously Monitor becomes the foundation of Step 5 and the cyclical nature of the entire methodology, ensuring that Zero Trust remains adaptive and responsive to evolving threats and business changes
ZT 5 Steps and the NIST RMF
Zero Trust is a cyclical, incremental process. Every phase informs the next, and ongoing monitoring ensures defenses remain effective. By building resilience into every step, organizations can better prevent, survive, and recover from breaches.
| Zero Trust Step | NIST RMF (SP 800-37) Step/Task | Enterprise Lifecycle Analogue |
|---|---|---|
| Define Protect Surface | Prepare (Task P-9, P10, P-12) + Categorize | Asset Inventory and Criticality Mapping |
| Map Transaction Flows | Prepare (Task P-11, Task P-13) | Workflow and Data Flow Mapping |
| Build Zero Trust Architecture | Select Security Controls | Security and Systems Architecture |
| Create Zero Trust Policy | Implement + Assess + Authorize | Access Control Rules and Governance |
| Monitor and Maintain | Continuous Monitoring | Continuous Audit and Process Improvement |
Table 4. Steps of the Five Step Process and their relationship to the NIST RMF
Key Concepts: Protect Surface and DAAS
-
DAAS: The specific Data, Applications, Assets, and Services (DAAS) that, if disrupted, would have a significant operational, regulatory, or reputational impact on the organization. These components form the foundation of the protect surface and require the most rigorous security controls and continuous monitoring
-
Protect Surface: The protect surface encompasses an organization’s most vital business systems, specifically those DAAS elements that are critical to operational resilience and must therefore receive continuous protection. These systems are prioritized and ranked by their business criticality, regulatory requirements, and current security maturity levels, with continuous reassessment to adapt to evolving business needs and threat landscapes
The Five Steps of Zero Trust Implementation
Step 1: Define the Protect Surface
General CSA Step 1 Guidance: Defining the Zero Trust Protect Surface
Start by identifying the organization’s protect surfaces, which includes business information and operational systems which are composed of data, applications, assets, and services (DAAS elements). Unlike the traditional attack surface, protect surfaces are precise and actionable, and are viewed from the inside out, rather than outside in.
Key Activities
- Business System Inventory: Identify and classify PII, PHI, IP, legal/claims systems, IoT devices, APIs, and SaaS platforms. Advanced asset discovery and classification tools can provide visibility into dependencies and exposure
- Stakeholder Validation: Validate via cross-functional workshops, active scanning, and cloud asset mapping
- Business Impact Analysis: Rank DAAS elements by regulatory, operational, and reputational impact. The BIA also provides insight into priorities, dependencies, and success criteria
- Baseline and Gap Assessment: Compare current state security posture to CSA, CISA, DoD Zero Trust, and NIST 800-207 benchmarks
- Metrics and KPIs: Use dashboards for real-time risk posture, DAAS coverage, and segmentation adoption rates
- Prioritization: Rank order the business systems/protect surfaces for Zero Trust and resilience implementation purposes by their criticality and vulnerability, starting with the most critical and most vulnerable systems first.
Analogy
Instead of policing an entire city, focus elite forces solely on “the vault.”
Resilience Enhancement
Business continuity planning, comprehensive backup, geographic and logical redundancy, and isolation protocols should be embedded into the DAAS inventory process. This guarantees that critical assets can continue operation or be quickly restored.
Case Study
In the 2022 Colonial Pipeline ransomware attack, a lack of effective segmentation and DAAS mapping caused a complete shutdown of operations. A lack of planning to remain viable during the incident (e.g., manual operation) further complicated the situation. However, with DAAS redundancy, some services could have stayed online.
Step 2: Map the Transaction Flows
General CSA Step 2 Guidance: Map the Transaction Flows for Zero Trust
Step 2 is executed iteratively for each business system/protect surface in turn, in the order in which they were prioritized in Step 1. The key activities in Step 2 are validating the data, applications, assets, and services (DAAS elements) they are comprised of and developing a thorough understanding of how the system works and its current state security and resilience maturity. Mapping data and access flows reveals dependencies, interactions, and vulnerabilities for the specific DAAS elements, external integration points. It also helps identify single points of failure that can be remediated in subsequent steps to improve the resilience of the system.
Key Questions
- Who accesses the DAAS? (internal users, contractors, third parties, non-person entities)
- What resources do they use? (databases, apps, APIs)
- When is access performed? (time patterns, anomalies)
- Where is access coming from? (device, network, location)
- Why is access justified? (purpose, job function)
- How is access performed? (security controls, encryption, MFA, VPN, ZTNA)
Mapping Action Table
| Action | Objective | Tools | Compliance Alignment |
|---|---|---|---|
| Diagram workflows/flows | Visualize interactions | SIEM, NDR, BPM | HIPAA, PCI, NYDFS |
| Document user/device access | Record access patterns | IAM, MDM, PAM | HIPAA, PCI DSS |
| Map dependencies | Reduce lateral risk | Dependency discovery tools | HIPAA, NYDFS |
| Define baselines/anomalies | Improve early detection | UEBA, SIEM | HIPAA, PCI DSS |
| Map flows to regulations | Ensure audit readiness | Compliance crosswalk | HIPAA, PCI, NYDFS |
Table 5. Actions, Objectives, Tools, Compliance Alignment
Resilience Enhancement and Case Study
Mapping allows for fast rerouting, segmentation, and creation of failover plans. For instance, organizations impacted by the 2023 MOVEit breach that had detailed data flow mapping could quickly resume operations by switching to backup systems, minimizing business disruption.
Step 3: Build a Zero Trust Architecture
Design architectures that enforce least privilege, real-time verification, and segmentation.
Key Technologies
- IAM and MFA for strong identity assurance
- Implementation of the concept of least privilege
- Zero Trust Network Access (ZTNA) for context-aware network access
- EDR, cloud access security broker (CASB) for endpoint/cloud threat enforcement
- SIEM/DLP for real-time analytics, threat detection
- Policy Decision and Enforcement Points (PDPs and PEPs) for granular, dynamic rule enforcement
Analogy
Rather than a single security checkpoint at the airport entrance, Zero Trust architecture creates intelligent verification points throughout the environment, similar to how a secure research facility requires badge verification, biometric confirmation, and escort authorization at each laboratory door, with different access requirements based on the sensitivity of each area and the specific research being conducted.
Resilience Enhancement
Integrate network redundancy, automated failover, and AI-driven rapid response triggers. This strategy contains breaches, maintains uptime, and enables faster restoration. Micro-segmentation, especially in critical manufacturing or OT networks, can be lifesaving.
Resilience emphasizes:
- Single Points of Failure (SPOF)
- Concentration Risk (risk aggregation)
- Counterparty Risk
- Contagion
- Cascading Risks
Case Study
In the NotPetya 2017 supply chain attack, companies with flat network architectures suffered total shutdowns, while those with robust micro-segmentation and strong Zero Trust principles could quickly resume critical operations.
Step 4: Create a Zero Trust Policy
Establish strict, testable policies using the Kipling Method (Who, What, When, Where, Why, How).
Policy Features
- Enforce least privilege and just-in-time access
- Mandate MFA/encryption for sensitive resources
- Require comprehensive access logging and justification
- Only allow connections from compliant, auditable sources
- Regularly conduct red-team and incident simulation exercises
- Log, recertify, and manage all exceptions
####
Analogy
There is no “master key;” each transaction requires tailored verification.
Resilience Enhancement
Clearly defined, flexible policies enable immediate privilege adjustment in a crisis, automate incident containment, and ensure that recovery procedures meet audit standards.
Case Study
As reported in an UpGuard Report in a 2023 international banking ransomware event, robust Zero Trust policies enabled rapid credential lockdown, failover execution, and customer assurance, thereby limiting both damages and regulatory exposure.
Step 5: Monitor and Maintain
Continuous, automated, real-time oversight is key to maintaining effective Zero Trust operations and compliance.
Metrics/KPIs
- DAAS inventory and coverage percentage
- Number of flows mapped and segmented
- Static privilege reduction over time
- Mean Time to Detect (MTTD) / Mean Time to Respond (MTTR) improvements
- Audit preparedness across HIPAA, PCI, DORA, and so on
- Recovery/restoration efficiency
Resilience Enhancement
Routine drills and post-incident reviews drive ongoing improvement. Automated analytics and SOAR playbooks enable immediate mitigation and the incorporation of lessons learned.
Case Study
A ZScaler report shows hospitals with mature Zero Trust monitoring have reduced ransomware recovery times from weeks to under 72 hours, thereby protecting patient care and revenue.
Zero Trust Implementation Process for OT
Applying Zero Trust principles to Operational Technology requires fundamental recognition that OT/ICS systems operate with distinctly different objectives and constraints than enterprise IT, as described earlier in the Operational Technology (OT) Resilience section. While IT systems prioritize the traditional CIA triad (confidentiality, integrity, availability), OT/ICS environments were designed primarily for safety, reliability, and uptime—where availability far outweighs other considerations. This difference has profound implications for security policy implementation. For example, while an enterprise IT policy might lock out a user after three failed authentication attempts, applying the same policy to an OT environment could lock operators out of critical Human-Machine Interfaces (HMI) during emergencies when human safety is at risk. Similarly, while patching is standard practice in IT vulnerability management, it represents the appropriate mitigation less than 10% of the time in OT/ICS environments, where system stability and uptime take precedence.
The five-step Zero Trust implementation process—(1) defining the protect surface, (2) mapping operational flows, (3) building a Zero Trust architecture, (4) creating Zero Trust policies, and (5) ongoing monitoring and maintenance—requires careful adaptation for OT/ICS contexts.
Step 1 demands collaboration between IT security professionals and OT engineers to identify critical cyber-physical assets across all levels of the Purdue Model (a common architectural pattern used in OT), from field devices (Level 0) through enterprise systems (Level 4-5). Asset inventory in OT presents unique challenges: many systems use proprietary protocols specific to industrial environments (Modbus, PROFINET, OPC, MQTT), lack standard operating systems, and cannot support traditional discovery tools like NMAP, which can actually cause failures in sensitive field devices.
Step 2, mapping operational flows, shifts terminology from IT’s “transaction flows” to “operational flows” and “process flows” that better reflect the continuous, interconnected nature of industrial processes. This mapping must account for the ISA/IEC 62443 zone and conduit model, where segmentation ideally ensures no single path traverses more than one Purdue Model level, and must identify patterns that surface reusable architecture building blocks while planning for more granular microsegmentation as the Zero Trust program matures.
Step 3, building the Zero Trust architecture, requires strategic placement of Policy Enforcement Points (PEPs) that accounts for OT/ICS realities. While modern IT applications readily support software-based Zero Trust agents, the lower levels of the Purdue Model (Levels 0-1) comprise legacy systems, stripped-down operating systems, and PLCs that cannot support software clients. In these scenarios, organizations must retrofit infrastructure to enable policy enforcement, often implementing network-based controls at Layer 2 or Layer 3 rather than the preferred Layer 7 application controls. Critical to OT resilience is ensuring redundancy across both control and data planes—including both PEPs and PDPs—to eliminate single points of failure and safeguard availability.
Step 4, creating Zero Trust policies, must be custom-tailored to each protect surface’s specific protocols, data types, and criticality levels, with policies that account for safety implications and operational constraints that don’t exist in IT environments.
Step 5, ongoing monitoring and maintenance, takes on heightened importance in OT/ICS environments while requiring specialized approaches. Organizations must use OT-aware monitoring tools that understand industrial protocols rather than relying on enterprise IT security solutions. Incident response planning must integrate both IT and OT considerations holistically, recognizing that recent critical infrastructure attacks have often originated on the enterprise IT side before impacting OT systems. Organizations should engage specialized OT incident response partners early—before an incident occurs—rather than attempting to apply general IT incident response practices. The relative stability of OT networks compared to enterprise IT actually provides an advantage: lower traffic volumes and more predictable baselines enable more granular visibility and higher-fidelity alerting. This monitoring should align with the SANS Top 5 Critical Controls for OT/ICS: (1) incident response, (2) defensible architecture, (3) visibility monitoring, (4) secure remote access, and (5) risk-based vulnerability management—each of which directly maps to the five-step Zero Trust implementation process and strengthens overall resilience.
Critical to successful Zero Trust implementation in OT/ICS is fostering organizational collaboration between previously siloed teams. IT security professionals, OT engineers, system operators, control room staff, and vendors must work together with executive sponsorship to understand the unique constraints, safety requirements, and operational realities of industrial environments. This collaborative approach—combined with incremental, risk-based implementation that starts with learning iterations on less critical systems—enables organizations to adapt Zero Trust principles to their specific OT/ICS context while building resilience. Organizations implementing Zero Trust in OT should leverage existing ISA/IEC 62443 documentation, zone and conduit models, and compliance evidence as foundations, progressively maturing their approach while maintaining the operational continuity and safety that are paramount in critical infrastructure environments.
Zero Trust Myths and Realities
| Myth | Reality | Risk if Believed |
|---|---|---|
| Zero Trust is a product | Zero Trust is a strategic framework enabled by technology, policy, and procedures—not a single product or solution | Vendor lock-in, wasted investment |
| Only about identity/MFA | Goes beyond identity to encompass users, devices, applications, data, workflows, and networks | Missed threats and attack vectors |
| There are Zero Trust products | No technology alone is considered Zero Trust; it’s enabled by integrating multiple technologies, robust policy, and operational procedures | Incomplete implementation, false sense of security |
| Too complex | Zero Trust is designed for incremental, manageable adoption using clear design principles | Paralysis, failure to start |
| Too costly | While some investment is required, Zero Trust reduces breach costs and long-term risk, often utilizing existing technologies | Higher long-term expenses |
| One-time project | Zero Trust demands ongoing governance and continuous improvement to stay effective | Risk drift, compliance decay |
| Blocks productivity | A well-designed Zero Trust environment enables secure, agile access and business operations | Dangerous workarounds, shadow IT |
| Only IT’s job | Zero Trust requires board/executive sponsorship and organization-wide participation | Underfunded, fragmented programs |
| Replaces current tools | Zero Trust builds on and integrates with existing investments, enhancing current tools with new policies, controls, and procedures | Tool chaos, wasted resources.\ |
| Not for cloud/hybrid | Zero Trust is especially suited for cloud, remote, and hybrid environments, as it operates independently of network perimeter | Unsafe hybrid deployments |
Table 6. Zero Trust Myths and Reality
Key Takeaways for Boards and Executives
“He who defends everything defends nothing.” - Frederick the Great of Prussia
“As security architects, our responsibility is not to defend everything equally, but to defend the right things—the assets that are vulnerable, exposed, and critical to the business.” - Jim Shor
- Align defense strategies to defend what matters. Focus on DAAS, not indiscriminately on everything
- Secure executive sponsorship; it’s non-negotiable for success
- Pilot Zero Trust in the most critical areas; demonstrate ROI, resilience, and compliance
- Operationalize compliance; embed audit and resilience checks in policy and practice
- Recognize that Zero Trust is a mindset and culture shift, not just a technology upgrade
Operationalizing Zero Trust Through Ongoing Resilience Testing
The main objective of resilience testing is to confirm that organizations have met the requirements in their Business Impact Analysis (BIA). The BIA identifies the systems, processes, and data that are crucial to business operations, the effects of disrupting them, and the recovery time goals that need to be achieved. By validating the controls, procedures, and technologies put in place using the Zero Trust five-step methodology, resilience testing ensures that the protection and recovery capabilities identified as necessary in the BIA are actually delivered.
Resilience testing expands on earlier tests, including vulnerability assessments, penetration tests, compliance audits, and security control validations. Unlike previous testing phases, which pinpoint weaknesses and validate individual controls, resilience testing assesses the overall effectiveness of the entire Zero Trust architecture under real-world stress conditions. This thorough approach ensures that theoretical security designs become practical defensive capabilities that can withstand and bounce back from actual attacks.
When issues are found during resilience testing, organizations must quickly notify the right technical teams, business stakeholders, and executive leadership. A formal tracking system ensures that problems are fixed within set timeframes, with progress tracked through ongoing monitoring processes set up in Step 5 of the Zero Trust approach. This creates a feedback loop where resilience testing results directly drive improvements to policies, technologies, and procedures, boosting the organization’s overall Zero Trust maturity and operational resilience.
Testing of resiliency is fundamentally aligned with the Zero Trust Principle “Never Trust, Always Verify.” Given that resilience primarily requires proactive and preventive actions, as well as an incident plan to react to events that occur, testing is governed by the methodology and actions that an organization implements. Those responsible for testing play a key role in contributing to the development of resiliency and incident recovery plans, helping to ensure that vulnerabilities are well understood. Developing and documenting the resiliency test plan becomes as essential as the resiliency plan itself.
Key Testing Practices for All Sectors
-
Frequent Supply Chain and Software Verification: Software from supply chains is a particular target for security attacks, so verifying their operation needs to be frequent. This is where a properly configured and tested Zero Trust approach significantly reduces risk by enforcing identity management, authentication, access policies, security functions, policy enforcement, and monitoring. The testing plan must verify that this is the case
-
Attribute-Based Access Control Testing: Test that attribute-based access control is enforced (e.g., a privileged user can only transact from an approved device/location/time). Done correctly, this would have prevented the infamous collapses of entire corporate infrastructure, even in the presence of social engineering
-
Breaches Happen and Lateral Movement Testing: Test for effective detection of lateral movement and abnormal discovery attempts, to prevent access to critical data and software as transaction flows cross your environments
-
Backup, Restore, and Disaster Recovery Validation: No testing can be regarded as complete until all backup systems are tested; restoration must be error-free, malware-free, and functionally operational
-
Incident Recovery Drills: Restoration of key business components should be tested repeatedly until recovery time is minimized and seamless, even in unexpected failover modes
-
Continuous Change Management: Network, cloud, and service changes should always prompt posture and controls re-testing, using auto-discovery and validation tools
-
Supply Chain, DevSecOps, and Collaboration: Work closely with internal and external partners to require code in memory-safe languages, DevSecOps practices, regression and staged testing, and use of SBOMs
-
Ongoing Evolution: Embrace automation and Agentic AI to reduce human error, improve scalability, and enable automated discovery and testing of every disruption vector. Resiliency testing never stops; it must be iterative and continually expanding
Sector Case Studies and Testing Applications
Colonial Pipeline (Critical Infrastructure)
The pipeline’s ransomware incident highlights the importance of proactively and continually testing network segmentation, policy enforcement, and incident recovery plans. One missed configuration or untested backup can have nationwide supply chain implications.
Zero Trust testing response:
- Run regular ransomware and lateral movement simulations
- Validate segmentation, privilege, and access controls
- Conduct backup/restore and failover exercises that emulate true operational crises
Transportation
Transportation agencies are increasingly targeted, requiring continual validation of networked endpoint authentication, real-time monitoring, and communications failover in incident scenarios.
Zero Trust testing response:
- Periodic incident response/tabletop exercises for service outage
- Automated discovery and validation of new connected devices
- Role-based access policy enforcement, tested after every system change
Electric Grids
Electric utilities face cross-domain risk between OT/IT environments and large-scale supply chain attacks. OT assets demand especially rigorous, scenario-based failover drills and restoration testing.
Zero Trust testing response:
- Scheduled simulation of black-start/grids-out recovery and restoration
- Quarterly OT network segmentation and access control validation
- Supply chain device/software onboarding and runtime tests
Financial Services
Threats range from targeted ransomware to credential abuse and fraud. Compliance requires not just audit, but also auditable, continuous testing of access policy, transaction flows, and recovery points.
Zero Trust testing response:
- Continuous privilege escalation detection and validation
- Routine red-team and incident restoration drills
- Live vendor/supply chain risk tests as part of operational controls
Healthcare
With patient safety and PHI at stake, organizations must conduct continuous, automated validation of ransomware backup and recovery, as well as regulatory breach notification response.
Zero Trust testing response:
- Quarterly (or more frequent) backup/restore drills, with verification for malware-free recovery
- Access management validation for all user/device privileges
- Vendor system onboarding and update testing for supply chain risk mitigation
Carlsberg Brewery
Carlsberg’s resilience approach, spanning digital assurance, strategic scenario planning, and continuous risk analysis, exemplifies industry best practice in repeatable resiliency test plan implementation.
Zero Trust testing response:
- Frequent scenario-based restoration and failover drills implemented globally
- Automated cloud security posture management and validation
- Regulatory, supply chain, and product restoration exercises, tailored to local and global risk
Five-Step Process Closing
Zero Trust is now a fundamental expectation from regulators, insurers, partners, and customers. Trust-based models are obsolete and risky. Adoption of the CSA five-step Zero Trust implementation lifecycle prevents breaches, stops lateral movement by attackers, ensures continuous verification, strengthens compliance, and embeds resilience at the core of business operations. Success requires ongoing executive leadership and a focus on constant improvement.
Conclusion
Resilience is the “ability to remain viable amidst adversity.”
As organizations face growing complexity and interconnectivity, resilience becomes a critical business priority, especially in sectors like finance and energy.
Unlike traditional disciplines, resilience relies on a cooperation of technology, people, process, and organizational controls across the entire cyber lifecycle of identity, protect, detect, and respond.
To ensure alignment of the business strategy, security architecture, and operations we use the Business Impact Analysis (BIA) to establish priorities and to set Minimal Viable Service Levels (MVSLs). The results of the BIA are the requirements for architecture, design, development, testing, and operational phases.
To ensure proper authority and reinforce alignment, we appoint an Operational Resilience Executive responsible for ensuring the organization meets its resilience objectives.
In resilience, we pay heightened attention to the impact from external factors (e.g., supply chain) and how disruptions within our organization impact others (e.g., customers). We especially look for and strive to eliminate:
- Single Points of Failure (SPOF)
- Counter Party Risk
- Risk Aggregation
- Cascading Risk
- Contagion
Useful References
What follows are additional references not necessarily included in the body of the document that the reader may find useful.
General Resilience
| [CSA Zero Trust Advancement Center (ZTAC) | CSA](https://cloudsecurityalliance.org/zt/resources/) |
ISACA What is Resilience and How Does it Promote Digital Trust
RESILIENCE FIRST Promoting Financial Stability by Planning for Disruption
| [THE POWER OF TECHNOLOGY RESILIENCE: A FRAMEWORK FOR THE INDUSTRY | DTCC](https://www.dtcc.com/dtcc-connection/articles/2022/june/08/power-of-technology-resilience) |
| [Designing Highly Resilient Financial Services Applications Based on a reference implementation developed for The Depository Trust & Clearing Corporation | DTCC](https://www.dtcc.com/-/media/Files/Downloads/DTCC-Connection/Designing-Highly-Resilient-Financial-Services-Applications.pdf) |
| [CCM Video Series: BCR - Business Continuity Mgmt and Op Resilience | CSA](https://cloudsecurityalliance.org/artifacts/ccm-video-series-bcr-business-continuity-mgmt-and-op-resilience) |
Creating and Maintaining a Definitive View of Your Operational Technology (OT) Architecture
Zero Trust
| [Zero Trust Architecture Implementation | CISA](https://www.dhs.gov/sites/default/files/2025-04/2025_0129_cisa_zero_trust_architecture_implementation.pdf) |
| [Zero Trust Guidance for Critical Infrastructure | CSA](https://cloudsecurityalliance.org/artifacts/zero-trust-guidance-for-critical-infrastructure) |
| [Zero Trust Guiding Principles v1.1 | CSA](https://cloudsecurityalliance.org/artifacts/zero-trust-principles-v-1-1%20) |
| [Zero Trust Architecture | NIST SP 800-207](https://nvlpubs.nist.gov/nistpubs/SpecialPublications/NIST.SP.800-207.pdf) |
NIST SP 800-207 Zero Trust Architecture. NIST, 2020.
International Standards and Regulations
Digital Operational Resilience Act (DORA), EU
Network and Information Systems Directive 2 (NIS2)
ISO 31000:2018 Risk management — Guidelines
Office of the Superintendent of Financial Institutions (OFSI), Canada Resilience (E21)
CER – European Critical Entity Resilience
PS21/3 – Building operational resilience (Policy Statement), UK
US Standards and Regulations
| [NIST CSF 2.0 | NIST](https://www.nist.gov/cyberframework) |
| [Federal Zero Trust Data Security Guide | CIO.gov, 2024.](https://www.cio.gov/assets/files/Zero-Trust-Data-Security-Guide_Oct24-Final.pdf) |
SP 800-160 Vol. 2, Developing Cyber-Resilient Systems. NIST, 2021.
National Cybersecurity Strategy
Strategy for Cyber-Physical Resilience
Organizational Strategy References
Chaos Engineering/Chaos Testing
| [Security Chaos Engineering: Improved Stress Testing | CSA, 2025.](https://cloudsecurityalliance.org/articles/security-chaos-engineering-fewer-blind-spots-and-improved-stress-testing-move-cisos-closer-to-cyber-resilience) |
| [Chaos Engineering for Enhanced Resilience of Cyber-Physical Systems | arXiv, 2021.](https://arxiv.org/pdf/2106.14962.pdf) |
| [Chaos Testing Best Practices | Apriorit, 2025.](https://www.apriorit.com/qa-blog/chaos-testing-best-practices) |
| [Chaos Engineering: A Multi-Vocal Literature Review | arXiv, 2016.](https://arxiv.org/html/2412.01416v1) |
How Capital One Performs Chaos Engineering in Production
CHAOS Engineering in the Cloud
Resilience Association – Knowledge Transfer of Resilience Ideas and Concepts
Resilience Association – Blogs
Breaches and Incidents
| [OPM Data Breach | ](http://OPM.gov) OPM.gov |
| [NotPetya Cyberattack | ENISA](https://www.enisa.europa.eu/news/enisa-news/notpetya-cyber-attack-lessons-learned) |
| [MOVEit Transfer Exploits | CISA](https://www.cisa.gov/news-events/alerts/2023/06/07/cisa-responding-moveit-transfer-exploits) |
| [Carlsberg Brewery Resilience | McKinsey](https://www.mckinsey.com/capabilities/risk-and-resilience/our-insights/how-carlsberg-thrives-with-resilience) |
Resilience Frameworks and Maturity Models
Cyber Resilience Capability Maturity Model (CR-CMM)
Cybersecurity Capability Maturity Model (C2M2)
GRF Operational Resilience Framework (ORF)
Security and Exchange Board of India
Miscellaneous
Third-party cyber risks impact all organizations
What Types of Alerts Could I Receive From a SOC?
NIST Special Publication 800-34 Rev. 1 Contingency Planning Guide for Federal Information Systems%20%20www.highvaluetarget.org/hvt)
NIST IR 8286D Using Business Impact Analysis to Inform Risk Prioritization and Response
World Economic Forum (WEF) The Cyber Resilience Index: Advancing Organizational Cyber Resilience
Antifragility
Taleb, N. N. (2012). Antifragile: Things that gain from disorder. Random House
Video Recordings
| [Leveraging Zero Trust for Digital Operational Resilience (DORA) and Beyond by Zscaler | CSA](https://circle.cloudsecurityalliance.org/viewdocument/leveraging-zero-trust-for-digital-o?CommunityKey=76100168-bb90-4ba9-ae5f-31c9264d05c1&tab=librarydocuments) |
| [Business Continuity Management and Operational Resilience (BCR) | CSA](https://www.brighttalk.com/webcast/10415/629366) |
| [The Future of Cyber Resilience and Risk Management: Tackling AI and Business Continuity | WWT](https://www.wwt.com/video/the-future-of-cyber-resilience-and-risk-management-tackling-ai-and-business-continuity) |
Technical References
| [Infrastructure Resilience Planning Framework (IRPF) | CISA](https://www.cisa.gov/sites/default/files/2024-03/infrastructure-resilience-planning-framework03-22-2024.pdf) |
| [Resilience Planning Program | CISA](https://www.cisa.gov/resources-tools/programs/resilience-planning-program) |
Cybersecurity and Financial System Resilience Report
What is Resilience and How Does It Promote Digital Trust, ISACA Journal, Issues, 2024, Volume 4
| [HIPAA | HHS](http://HHS.gov) |
| [PCI DSS v4.0 | PCI Security Standards Council](https://www.pcisecuritystandards.org/document_library?category=pcidss&document=pci_dss) |
| [Zero Trust Cybersecurity Standards | Identity Management Institute, 2024.](https://identitymanagementinstitute.org/zero-trust-cybersecurity-standards/) |
| [Theory and Application of Zero Trust Security: A Brief Survey | PMC, 2023.](https://pmc.ncbi.nlm.nih.gov/articles/PMC10742574/) |
Financial Services References
| [Cyber Resiliency in the Financial Industry 2024 | CSA](https://cloudsecurityalliance.org/artifacts/cyber-resiliency-in-the-financial-industry-2024-survey-report) |
The State of Cyber Resiliency in Financial Services
ENISA Threat Landscape: Finance Sector
European Central Bank (ECB). (2020). ECB Cyber Resilience Oversight Expectations for FMIs.